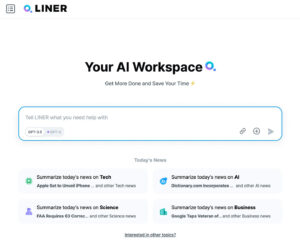
나를 가장 잘 이해하는 개인화 어시스턴트, LINER Copilot
안녕하세요, 머신러닝 엔지니어 카터입니다. 오늘은 조금 특별한 이야기를 해볼까 합니다. LINER에 새로이 들어서게 된 제품 라인업 “개인화 어시스턴트 LINER Copilot“이 그 주제인데요. LINER가 어떻게 개인화 어시스턴트라는 제품을 구현하게 되었는지, 우리는 해당 제품을 통해 어떤 문제를 해결하고자 하는지에 대한 소개를 글을 통해 드리고자 합니다.

많은 분들이 알고 계시듯, LINER는 오프라인에서 형광펜을 치며 학습하던 경험을 온라인으로 옮겨 사용자에게 학습 생산성을 제공하는 유틸리티 서비스로 시작한 기업입니다. 단순한 기능을 제공하던 서비스였지만 직관적인 인터페이스와 형광펜이라는 메타포가 주는 친숙함 덕분에 LINER는 초창기부터 전 세계적으로 많은 사랑을 받으며 성장할 수 있었습니다.
그러나 LINER는 설립 시점부터 제품을 세상에 내놓고 확장하기까지 “세상에서 가장 훌륭한 형광펜 유틸리티 서비스를 만들겠다”라는 목표를 지니며 달려온 적이 없었습니다. 예나 지금이나 LINER는 Help People Get Smart Faster 라는 미션을 해결하기 함께 모여 제품을 만들어 나가고 있습니다. 해당 미션에 대한 배경은 이 글에서 더 자세히 확인하실 수 있습니다.
이 여정에서 형광펜 유틸리티 서비스는 사용자에게 직접적인 효용을 제공하는 기능이자, 우리가 풀고자 하는 “정보의 홍수 문제“에 적합한 해결 도구를 갖추기 위한 데이터를 제공해줄 수 있는 인터랙션 데이터 인입부의 역할을 해주었습니다. 우리는 다년간 축적한 형광펜 사용 이력을 통해 사용자들의 선호 정보를 유추할 수 있게 되었고, 이를 기반으로 사용자에게 여러 효용을 줄 수 있는 기능을 제공해줄 수 있을 것이라 믿게 되었습니다.
LINER Discovery Platform
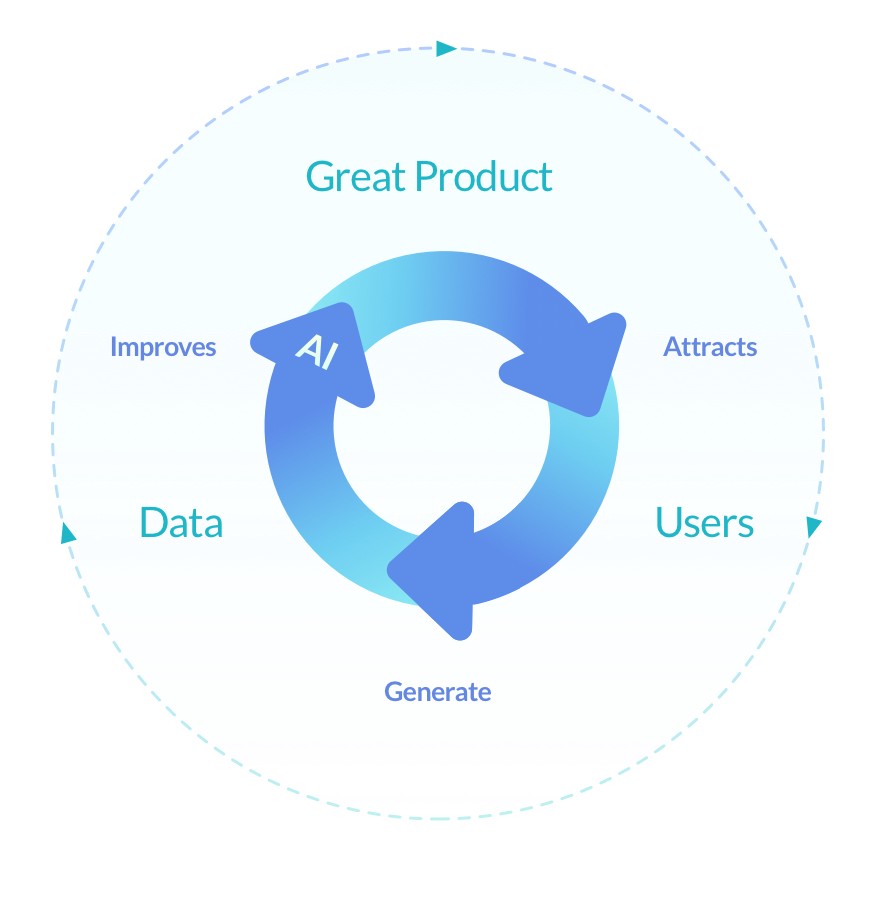
그렇게 LINER가 문제 해결을 위해 다음으로 집중하게 된 영역은 개인화 콘텐츠 추천 시스템이었습니다. 브라우저 익스텐션으로 동작하는 하이라이팅 유틸리티 서비스로부터 수집된 하이라이트 이력을 기반으로 개인화 콘텐츠 추천 시스템을 구축해, 사용자가 유틸리티를 사용할수록 자신을 보다 더 잘 이해해주는 서비스에 의해 정보 수집과 소비에 대한 도움을 받을 수 있는 선순환의 구조를 그려나간 셈인데요.
실제로 지난 2년 여간 LINER에서는 개인화 추천에 있어 많은 기술적 성장과 내재화가 이루어졌습니다. 당장 본 블로그를 둘러보시더라도 개인화 추천 발전의 흔적을 이곳 저곳에서 찾아보실 수 있으실 겁니다. 그렇다면 추천 시스템 (기술) 을 기반으로 한 추천 플랫폼 (제품) 의 구축이 온전히 성공적이었느냐하면 우리가 원하던 기준에는 미치지 못했다고 봐야하겠습니다.
그 배경에는 여러 이유가 있었겠지만, 가장 큰 원인은 익스텐션 사용자를 크로스 플랫폼 사용자로 전환하는 작업이 생각처럼 쉽지 않았기 때문이었다고 생각합니다. 실제로 브라우징 과정에서 유틸리티 서비스로부터 효용을 얻고 있는 사용자를 LINER 자체 웹 혹은 앱 플랫폼으로 불러 들이는 것은 어려운 일입니다. 플랫폼에 방문해야 할 직접적인 동인이 부족하기 때문입니다. 해당 부재를 콘텐츠 추천이라는 유즈 케이스로 메워보고자 했으나, 사용자들에게 해당 유즈 케이스를 각인시키는 점에 있어 기술적으로 그리고 경험적으로 부족했습니다.
결국 “1) 개인화 추천 시스템을 기반으로 콘텐츠 플랫폼을 구현해, 2) 익스텐션 사용자를 크로스 플랫폼 사용자로 전환시키며, 3) 제품이 사용자에게 주는 효용을 극대화하겠다”는 담대한 목표를 100% 달성하지는 못하였지만, 이 과정에서 우리는 많은 배움을 얻었습니다.
우리는 이 과정을 통해 사용자들에게 개인화 서비스를 제공하기 위해 필요한 기술과 인프라를 A to Z로, 높은 퀄리티로 구축할 수 있는 팀이 되었습니다. 또한 사용자가 어느 정도로 개인화에 반응하는지 혹은 단순 관심사나 최신성 등에만 반응하는 것은 아닌지에 대한 제품적 배움도 축적할 수 있었습니다. 그리고 마지막으로 단일 플랫폼 사용자를 크로스 플랫폼 사용자로 전환시키는게 얼마나 어려운 작업인지에 있어 실패로부터의 배움도 얻을 수 있었습니다.
(이는 어렵기 때문에 “도전해서는 안된다”라는 의미는 아니며, 어려운 일이니 만큼 제품적/기술적 마일스톤을 촘촘히 설정해 페이즈에 맞는 시도를 통해 해결해나가야 한다는 의미입니다.)
ChatGPT, The disruptor of Knowledge Systems
여러 성공과 실패로부터 배움을 이어오던 중, 2022년 11월 전 세계를 떠들썩하게 만든 녀석이 등장하게 됩니다. 이제는 소개를 하기도 식상해진 ChatGPT는 등장과 함께 “정보탐색” 문제를 해결하던 수많은 플레이어들에게 문제에 대한 재정의와 새로운 파훼책에 대한 강도 높은 고민을 요구하기 시작했습니다.
직접적으로 정보탐색이라는 키워드를 사용해가며 문제를 풀어오던 LINER도 그 예외는 아니었습니다. 우리는 ChatGPT 등장 이후 우리가 풀던 문제 영역이 Disrupted 되었는지, 사람은 여전히 정보탐색이라는 문제를 겪고 있는지 혹은 미래에도 겪게 될 것인지 등에 대해 여러 이야기를 나누며 문제 진단에 나섰고 나름의 생각을 정립해나가게 됩니다.
논의의 가장 큰 골자는 정보탐색이라는 문제는 ChatGPT 등장 이후에도 유효한 문제라는 것입니다. 사용자들이 겪고 있는 정보탐색이라는 Pain에 대한 Pain-killer가 ChatGPT, ChatGPT + Search, ChatGPT + Specific Usecase 등으로 나타나게 된 것일 뿐이지, ChatGPT의 등장만으로 모든 정보탐색 문제가 해결되지는 않았습니다.
(쉬운 이해를 위해 ChatGPT로 통일하여 작성했으며, 위 단락에서 ChatGPT가 사용된 부분은 보다 상위 개념인 LLM으로 모두 치환할 수 있습니다.)
실제로 ChatGPT 등장 이후, ChatGPT 단일로만 해결하지 못하는 영역에 있어 여러 통합 시도가 일어나고 있는 것을 쉽게 확인할 수 있으실 겁니다. 최신성 부재와 환각 효과라는 문제를 해결하기 위해 검색 엔진을 결합한 Bing Chat, 사용자가 작업 중인 “코드 베이스”라는 맥락을 이해해야 효용을 제공할 수 있는 Github Copilot 등이 그 대표적인 예라 할 수 있겠습니다.
위 제품들은 모두 ChatGPT의 강력함과 더불어 약점을 대변하고 있다고 볼 수 있습니다. 바로 요구사항에 걸맞는 정보를 검색 엔진 혹은 현재 사용자가 위치한 작업 공간에서 불러올 수 있어야 올바른 일처리가 가능하다는 점입니다. 이같은 약점 덕분에 (?) 최근 벡터 서치를 위시한 검색 엔진 시장이 새로운 투자 기회로 열리고 있기도 합니다. 또한 사용자의 복잡한 요구사항을 해결하기 위해 여러 태스크를 복합적으로 수행하게 하기 위한 Chaining, 외부 툴과의 Integration 역시 ChatGPT 단일로 해결이 어려운 문제이므로 LangChain, llama-index와 같은 여러 엔지니어링 서드 파티가 발전하고 있습니다.
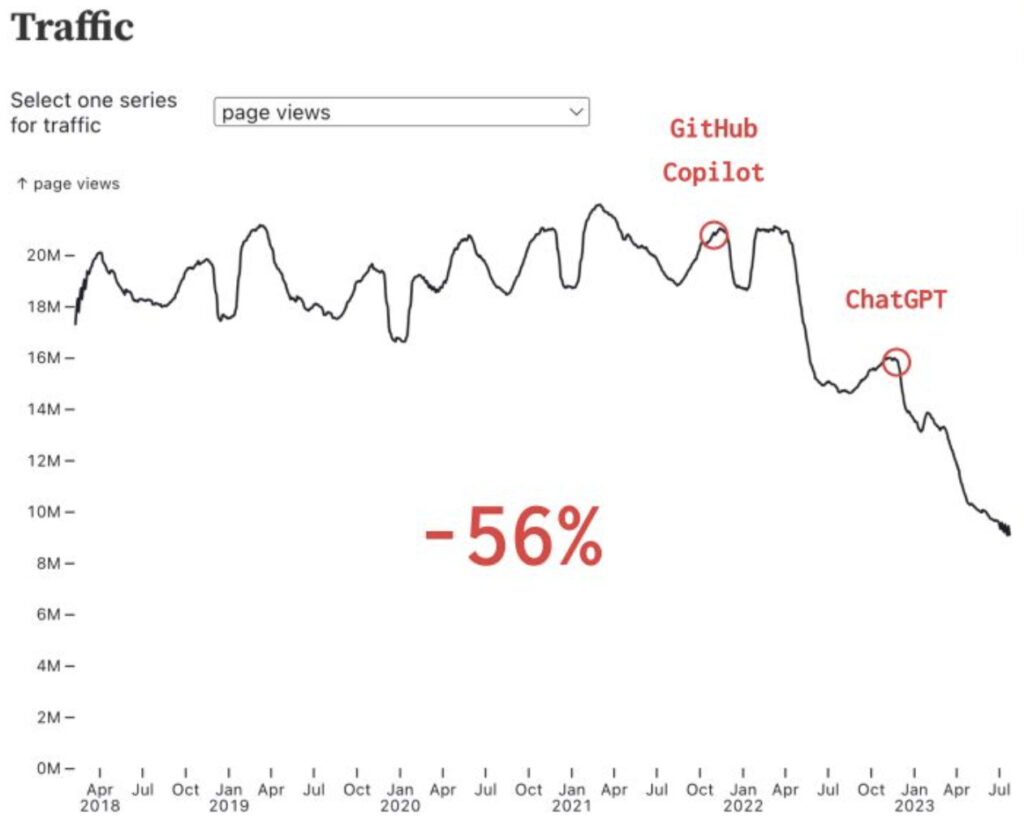
다시 정보탐색 문제로 돌아와보죠. 최근 ChatGPT 등장 이후, Stackoverflow의 트래픽이 지속적으로 우하향하고 있다는 이야기가 반복적으로 들려오고 있습니다. Stackoverflow가 특히나 조명을 받고 있을 뿐, 다른 정보탐색 서비스인 Quora, Reddit 등도 상황은 크게 다르지 않을 것입니다. 이에 대한 대답으로 Stackoverflow는 OverflowAI를, Quora는 Poe를, 그리고 Google은 Bard를 공개하며 정보탐색 영역에 있어 본인들이 지녔던 우위를 살리려는 시도를 이어오고 있습니다.
이처럼 바뀐 세상에는 바뀐 해결책이 필요합니다. LINER 역시 변화한 세상에서 우리가 가장 잘 할 수 있으면서, 미션에 부합하는 제품에 대한 고민을 이어오고 있습니다. 그리고 ChatGPT-Era의 정보탐색에서 LINER가 내놓은 대답은 “나를 가장 잘 이해하는 개인화 어시스턴트, LINER Copilot” 입니다.
개인화 어시스턴트, LINER Copilot
사실 LINER는 ChatGPT 등장 이후, 발 빠르게 제품에 ChatGPT를 도입하며 우리 제품과의 적합성을 점검하고 사용자에게 효용을 제공할 수 있는 기능에 대한 고민을 지속적으로 이어왔습니다. ChatGPT API 공개 이후 2주가 채 지나지 않은 시점에 공개한 LINER Chat, 익스텐션을 통해 PDF의 쉬운 학습을 돕는 PDF Copilot 등이 그 예입니다.
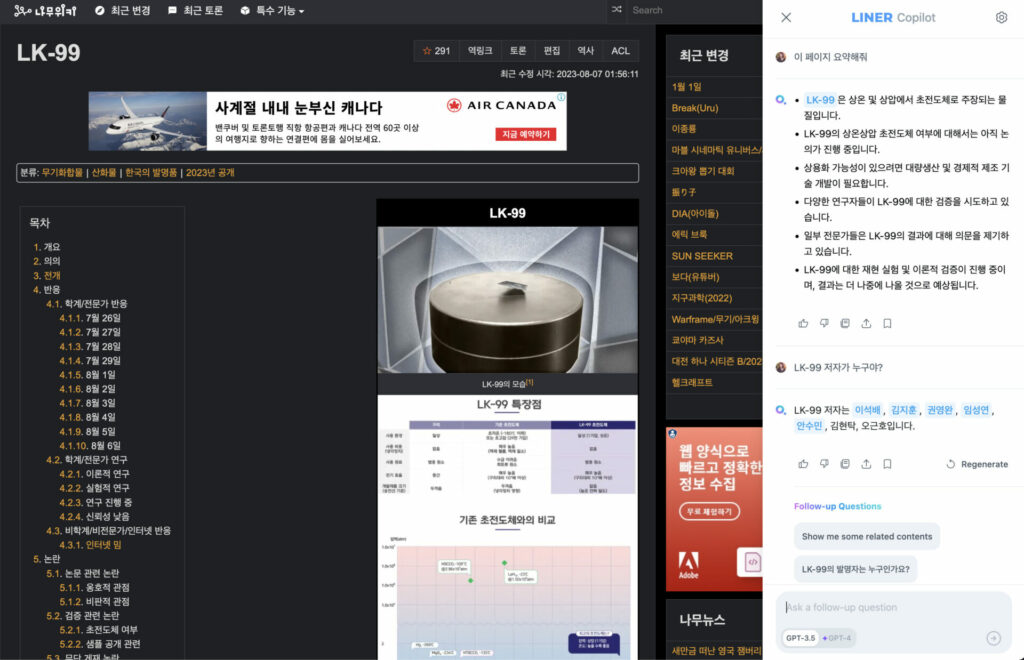
그리고 이 두 프로젝트는 현재 각각 Agent와 Grounding Copilot 프로젝트로 발전했습니다. 먼저 Grounding Copilot은 이름 그대로 특정 지식이나 정보에 “기반해 (Grounding)” 답변을 수행하는 Copilot입니다. 현재 LINER는 사용자가 Web page, YouTube, PDF 등의 콘텐츠를 소비하는 과정에서 해당 콘텐츠를 빠르게 훑어볼 수 있도록 도와주는 요약 기능, 콘텐츠를 모두 소비하지 않더라도 필요한 정보만 빠르게 찾아볼 수 있는 질의응답 기능 등을 제공하고 있습니다.
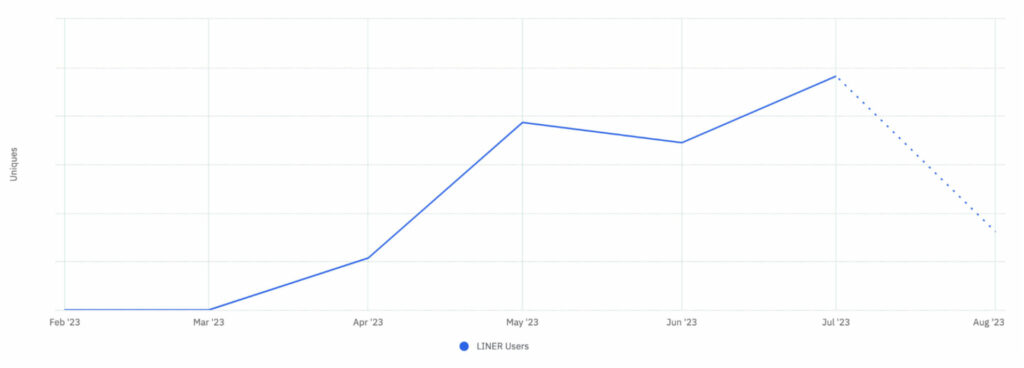
LINER 엔지니어링 팀은 본 기능의 구현을 위해 벡터 서치를 포함한 하이브리드 서치 (Term-matching search + Vector search + Boolean search) 시스템을 자체 구축하였으며, 그래프를 통해 확인할 수 있듯 출시 이후 지속적인 고도화와 사용성 개선을 통해 사용자 층을 꾸준히 쌓아 올려나가고 있습니다.
Grounding Copilot이 LINER 제품 라인업에서 지니는 의의는 다음과 같습니다. 첫 번째로, 우리가 기존부터 잘해오던 익스텐션 기반 플레이로 사용자 베이스를 더 단단히 할 수 있게 되었습니다. 두 번째로, LLM 기반 어플리케이션으로 정보탐색을 해결할 수 있겠다는 확신을 내부적으로 지닐 수 있게 되었습니다. 마지막으로 섬세한 기능 구현을 위한 기술적 요구사항을 파악하고 내재화 할 수 있게 되었습니다. Grounding Copilot은 익스텐션 기반의 제품이기에 사용자의 브라우징 여정을 함께 하며, 학습과 정보 습득 과정에 지속적으로 Seamless 하게 관여하는 방향으로 발전하게 될 예정입니다.
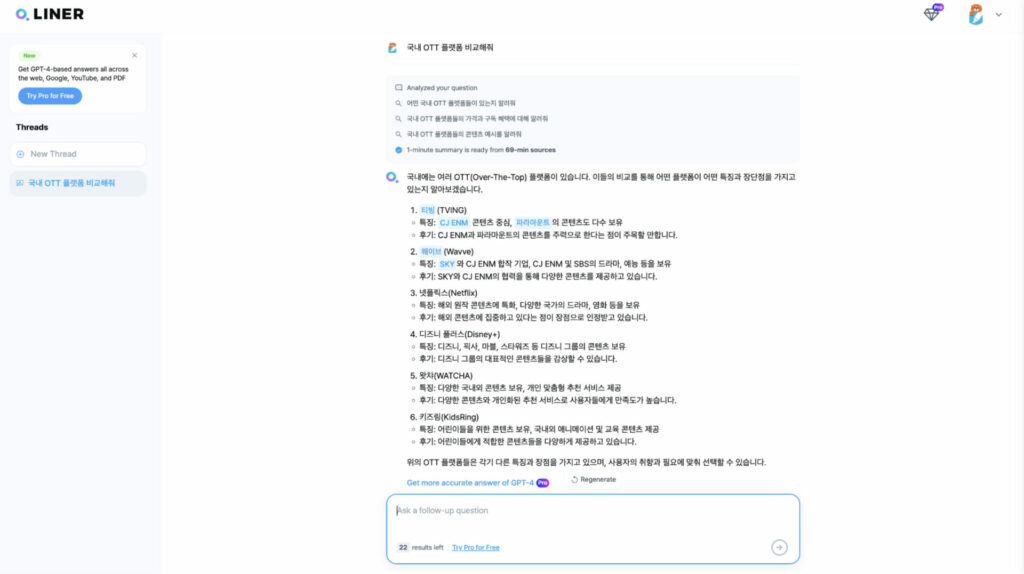
다음으로 LINER Chat에서 발전한 Agent는 플랫폼 기반 제품으로, 사용자의 복잡한 요구사항을 한 번의 요청만으로 해결해주기 위해 구현된 기능입니다. 위 예제에서 확인할 수 있듯, 사용자 입장에서는 하나의 질의이지만 시스템 입장에서는 여러 서브 태스크를 수행해야 정확한 답변이 가능한 질의를 자체적인 판단과 실행으로 대신해서 해결해주는 역할을 담당하게 됩니다.
해당 제품은 Autonomous Agent 개념에 기반해 개발되었으며, 사용자 질의가 들어왔을 때 복잡한 태스크인지를 판단하는 로직부터, 태스크를 작은 단위의 문제로 분할해 해결하는 프로세스, 최종 답변을 조합해 생성하는 로직까지 여러 복잡한 과정을 통해 구현되었습니다. Agent는 사용자가 적은 시간과 품을 들여 원하는 결과를 얻어갈 수 있도록 도와주는 원터치 워크스페이스로 발전하게 될 예정입니다.
새 시대에 맞추어 제품에 여러 변형이 가해지고 있지만, 우리가 풀고자 하는 문제와 지향점은 과거와 여전히 동일합니다. 우리는 여전히 사용자들이 더 적은 시간과 노력을 들여서, 더 많은 성장과 배움을 얻어 나가게 되기를 바라고 있습니다. 그리고 그 전환에 LINER가 가장 큰 기여를 하고자 하는 마음으로 제품 개발에 임하고 있고요.
LINER에 Help People Get Smart Faster 라는 최상위 미션이 있다면, LINER Copilot의 미션은 Help People Get More Done With Less Time and Energy 입니다. 사용자가 이전보다 적은 시간과 에너지를 들여, 더 많은 일을 수행해낼 수 있도록 돕겠다는 목표 하에 개발되고 있는 제품이라는 의미입니다. 이를 위해 LINER는 그간 축적해온 배움과 새로운 기술의 조화를 통해 새로운 사용자 효용을 지속적으로 만들어 나가고 있습니다.
맺으며…
LINER가 꿈꾸는 미래를 위해 제품을 만들어 나가는 여정은 여전히 흥미롭고 설레는 일입니다. 생각처럼 잘 풀리지 않아 힘든 날들도 많지만, 우리가 제시한 가설대로 사용자가 반응을 해주어 기쁘게 개선안을 적용하게 되는 날들도 있습니다. LINER Copilot 역시 이러한 고난과 즐거움의 과정을 통해 성장해나가고 있습니다.
마지막으로 본업이 엔지니어이니 만큼 LINER Copilot이 “기술적으로” 앞으로 어떻게 발전하기를 기대하는지를 기재하며 글을 마쳐볼까 합니다. 가장 큰 어려움이 예상되면서도, 관심있게 고민하고 있는 영역은 바로 “개인화”입니다. LINER는 사용자가 최근 어떤 문제에 관심이 많은지, 어떤 콘텐츠를 소비하는데 Copilot을 활용했는지 등을 파악할 수 있습니다. 그리고 이러한 사용자 인터랙션 데이터는 곧 개인화의 기반으로 활용될 수 있습니다.
Copilot 개인화의 경우, 기존 콘텐츠 추천과 다른 요구사항의 기술이기에 데이터베이스 구축부터 활용안에 이르기까지 새로이 고민해야 할 영역이 많이 있는 상황입니다. 현재는 인터넷이라는 데이터베이스에, 콘텐츠와 LINER 사용자라는 엔티티가 존재하고, 콘텐츠 소비 과정에서 발생하게 될 여러 액션들을 엣지로 치환해 Knowledge Base 개념으로 데이터베이스를 구축해 개인화 소스로 활용하는 안으로 고민을 쌓아가고 있습니다.

다음으로 자체 LLM 활용에 대한 연구 및 개발이 필요합니다. 지난 반년 간은 OpenAI 모델 기반으로 제품을 빠르게 개발하는데에 초점을 맞추어 왔습니다. Agent의 경우 모델의 Reasoning 역량이 받쳐주지 않는다면 구현이 어려운 제품이기도 하거니와, Mircosoft Build에서 Andrej Karpathy가 주장한 바와 마찬가지로 현존 가장 뛰어난 모델로도 구현이 어렵거나 불가한 기능은 현재 제작이 불가능한 제품이라 판단했기 때문입니다.
어느 정도의 개발이 이루어진 현 시점에서는 특정 컴포넌트의 경우 자체 LLM으로 대체가 가능하겠다라는 판단을 내릴 수 있게 되었습니다. 여기서 Reasoning 레이어는 근시일에 교체가 어렵다는 점을 인정하고 가야 합니다. 하지만, 레퍼런스를 토대로 답변을 생성하는 Answer Completer, 프롬프트에 입력된 콘텐츠를 요약해 반환해야 하는 Summarizer 등의 경우 자체 개발을 통해 대체가 가능할거라 판단하고 있습니다.
물론 최종적인 기술 교체의 의사결정은 API 지출 비용과, 인퍼런스 서비스 구축에 드는 인건비, 서버 운영비 등의 총합을 비교해 프로젝션하여 이루어지겠지만 최근 공개된 LLaMA2 그리고 이를 기반으로 맥락을 확장한 LLaMA-2-7B-32K의 성능으로 미루어 보아 충분히 연구와 개발을 진행할 가치가 있다고 생각하며, 기술의 내재화를 위해 해당 방향이 더 건전하다고 보고 있습니다.
이외에도 Reasoning 역량을 고도화하기 위한 LLM 이해도 바탕의 로직 개선, 검색 결과를 더 잘 활용하기 위한 Reranking, 그리고 리트리벌 메커니즘의 전반적인 고도화 등 기술적으로 풀고 싶은 문제가 굉장히 많이 남아 있습니다. 저희와 여러 기술적 어려움을 해결해나가며, 사용자에게 효용을 제공할 수 있는 제품을 만들고자 하는 분들의 많은 관심을 부탁드려봅니다.
학습과 업무에 들이는 시간이 줄어들었음에도 같은 산출량이 도출되는 미래를 그려봅니다. 이로 인해 사랑하는 지인, 가족, 연인과 더 많은 시간을 함께 나누거나, 혹은 더 많은 성장과 발전을 누릴 수 있게 되는 미래를 그려봅니다. 이 미래를 그려나가며, 치열하게 옳은 방향에 대해 동료들과 입씨름하며, 제품 개발 과정에서 희노애락을 느끼게 될 여정에 함께 해주세요. 긴 글 읽어주셔서 진심으로 감사합니다.