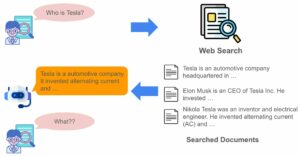
너, 내 비서가 돼라! LINER Autonomous Agent 구축기
안녕하세요, 머신러닝 엔지니어 에디입니다.
라이너 팀은 정보 탐색을 혁신하여 사용자들이 더 적은 시간과 노력으로 더 많은 일을 할 수 있게 도와주는 제품을 만들어나가고 있습니다.
현재 라이너 제품은 크게 두 가지로 구분해볼 수 있습니다. 웹 페이지나 유튜브, PDF 콘텐츠 등을 소비하는 과정에서 해당 콘텐츠에 기반해 요약, 질의응답 기능 등을 제공하는 Grounding Copilot과 사용자의 복잡한 요구사항을 자체적으로 판단하여 일을 대신 수행해주는 AI Workspace입니다.
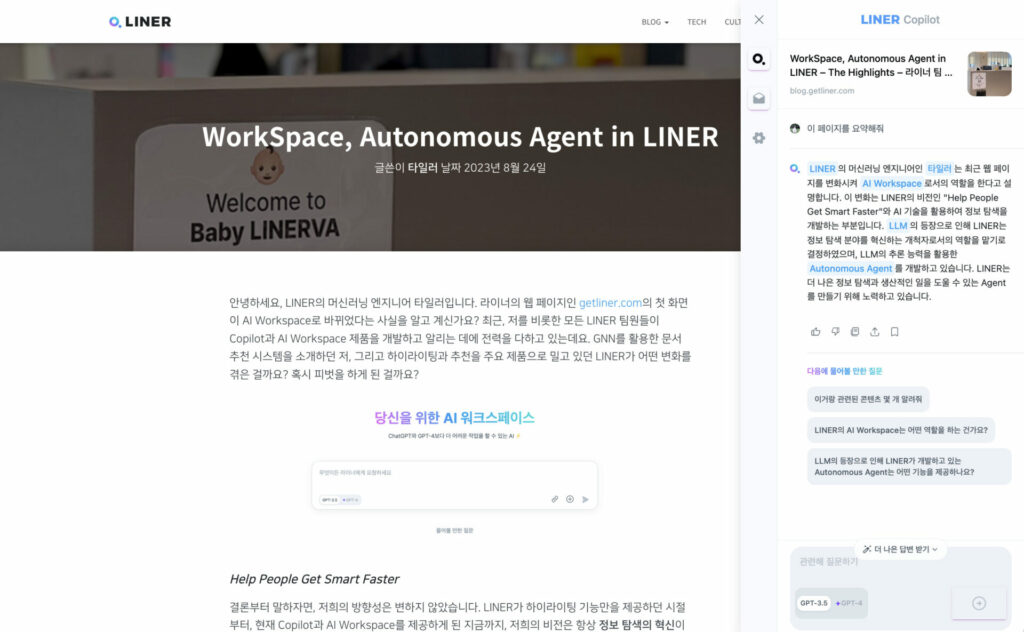
앞서 카터, 타일러의 블로그 글(“나를 가장 잘 이해하는 개인화 어시스턴트, LINER Copilot”, “WorkSpace, Autonomous Agent in LINER” )을 통해 하이라이팅 유틸리티였던 라이너가 코파일럿 기반의 제품으로 나아가게 된 배경, LLM을 활용한 Autonomous Agent의 개념과 라이너 워크스페이스에 대해 소개드렸는데요. 오늘은 저희가 워크스페이스에서 동작하는 Autonomous Agent를 구현한 과정에 대해 구체적으로 설명드리고자 합니다.
Autonomous Agent in LINER Workspace
기술적인 이야기를 꺼내기에 앞서, 아직 라이너 워크스페이스를 써보지 않으신 분들을 위해 워크스페이스에서 Autonomous Agent가 어떻게 동작하는지 그 과정을 간단히 소개해드리겠습니다.
라이너 웹 페이지(https://getliner.com/)에 접속하면 다음과 같은 AI 워크스페이스가 나타납니다. 텍스트 입력 창에 지금 수행해야 할 태스크를 입력하면 Autonomous Agent가 그 태스크를 대신 수행해주는데요.
예를 들어 사용자가 “Make a report of comparing OTT platforms.”라는 요청사항을 입력하게 되면, Autonomous Agent는 요청받은 일을 완수해내기 위해 필요한 작은 서브 태스크들을 만듭니다.
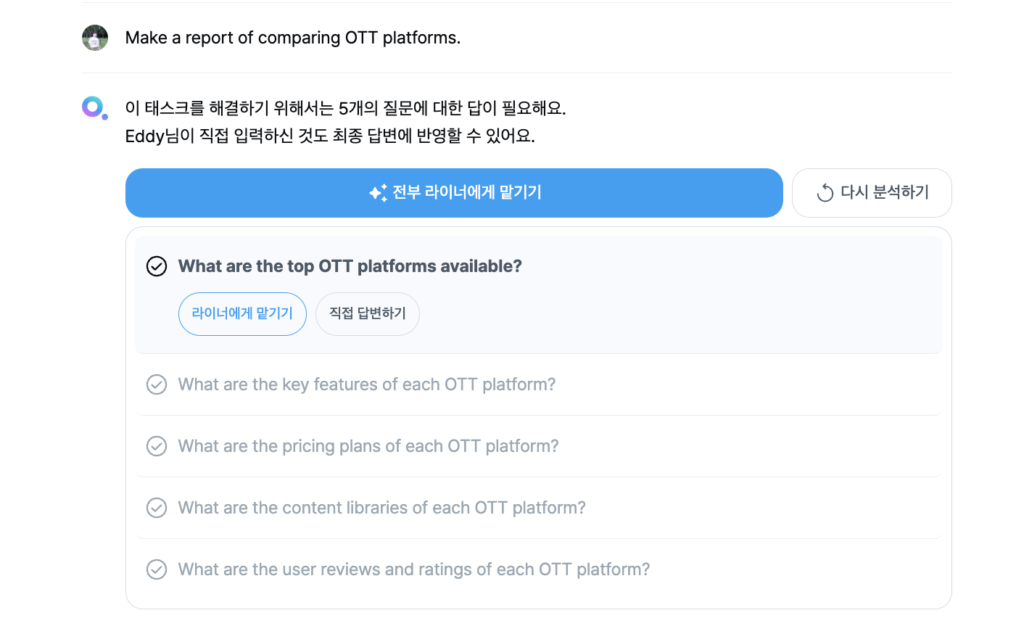
이후 Agent는 각각의 서브 태스크들을 수행하고 그 결과를 종합하여 최종 답변을 도출합니다. 사용자 입장에서는 필요한 정보를 탐색하기 위해 여러 번 구글 검색을 하고 자료를 정리할 필요 없이, 1분도 채 지나지 않아 한 편의 완성된 리포트를 받아볼 수 있습니다.
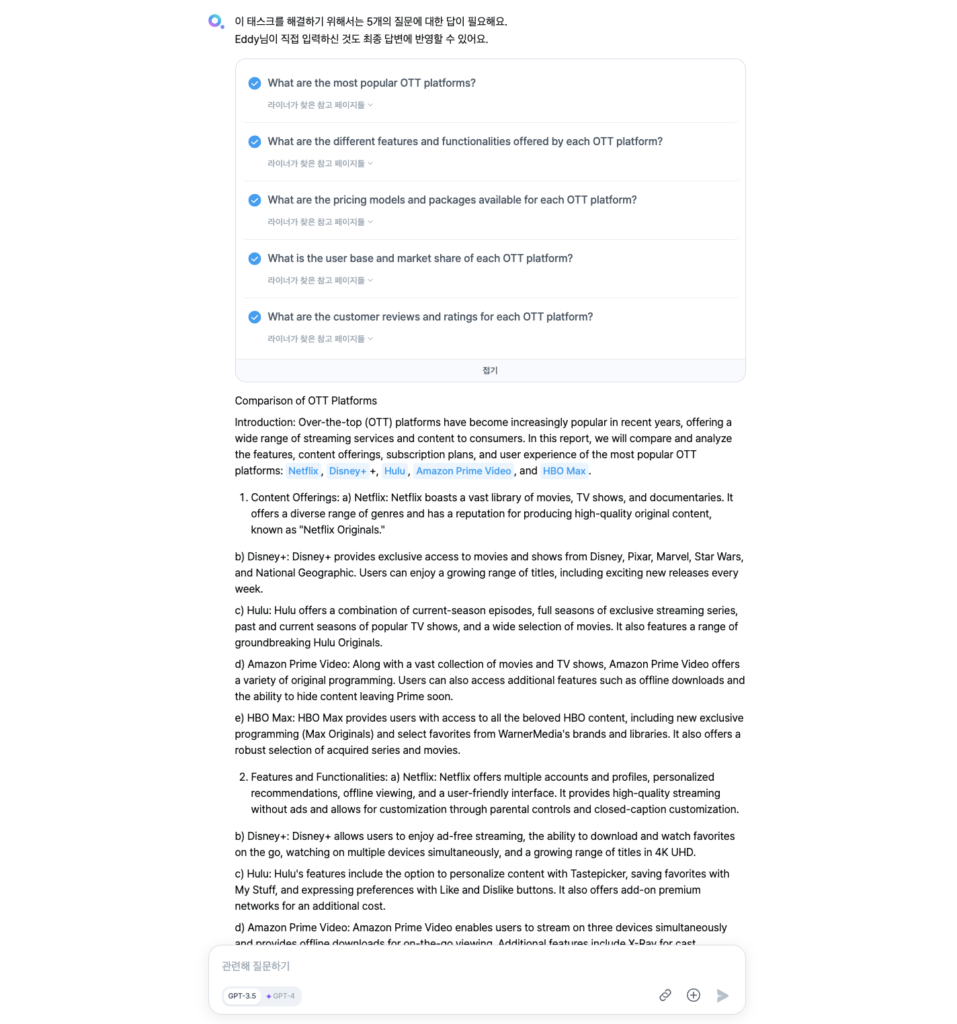
이처럼 라이너 워크스페이스에 도입된 Autonomous Agent는 질문에 대한 정보를 제공하는 것을 넘어 실제로 사용자가 생산적인 일을 해내는 것까지를 돕는, 일종의 개인 비서 역할을 수행하고 있습니다.
Core Components
Autonomous Agent는 여러 판단을 자율적으로 수행하여 사람의 일을 대신 수행해주는 시스템을 말합니다. 이러한 Autonomous Agent의 핵심 컴포넌트는 Planning과 Memory, Tool Use라고 할 수 있습니다. 우선 사용자로부터 요청받은 복잡한 태스크를 수행하기 위한 계획을 세우고, 어떤 도구를 이용하여 그 계획을 실행할 것인지를 자체적으로 결정합니다. 그리고 중간중간 액션을 수행하고 관찰한 결과를 메모리에 저장해 다음 태스크 수행에 반영해나갑니다.
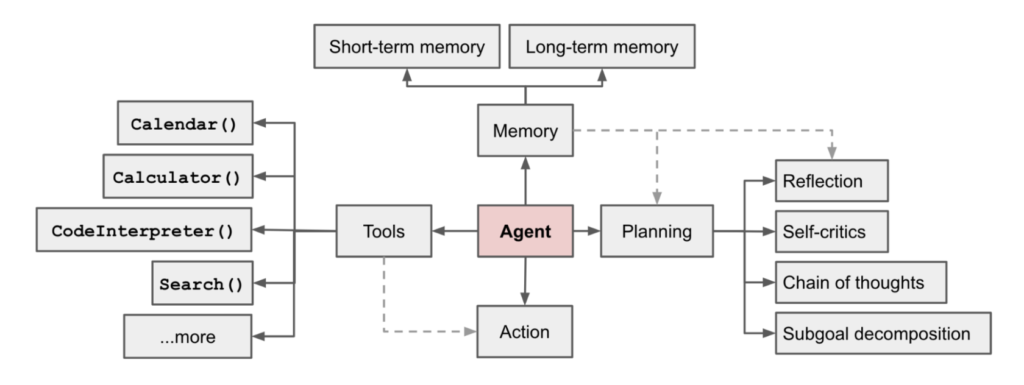
따라서 Autonomous Agent를 만들기 위해서는 각 컴포넌트를 어떻게 구성할지에 대해 생각해보아야 합니다. 구체적으로는 (1) 복잡한 태스크를 수행하기 위한 계획을 어떤 방식으로 세울 것인지, (2) 어떤 정보들을 메모리에 저장하고 불러와 태스크 수행에 활용할 것인지, 그리고 (3) Agent에게 어떤 도구들을 쥐어줄 것인지에 대한 고민이 필요합니다.
이 중 저희가 가장 많이 고민을 했던 것은 (1) 복잡한 태스크를 수행하기 위한 계획을 어떻게 세울 것인지에 대한 부분이었습니다. 애초부터 계획이 잘못되어버리면 이후 아무리 태스크를 잘 수행한다고 해도 사용자의 복잡한 요구사항을 모두 만족하는 답변을 내놓기가 어렵기 때문에, Planning 단계는 특히 중요합니다. 따라서 LLM의 추론 역량을 극대화하여 올바른 계획을 세우게 만드는 것이 핵심이었는데요. 관련 논문을 탐색하던 중 Planning 단계에 적용해볼만한 연구 두 가지를 찾아 적용해보게 되었습니다. 바로 Plan-and-Solve와 Self-Ask입니다.
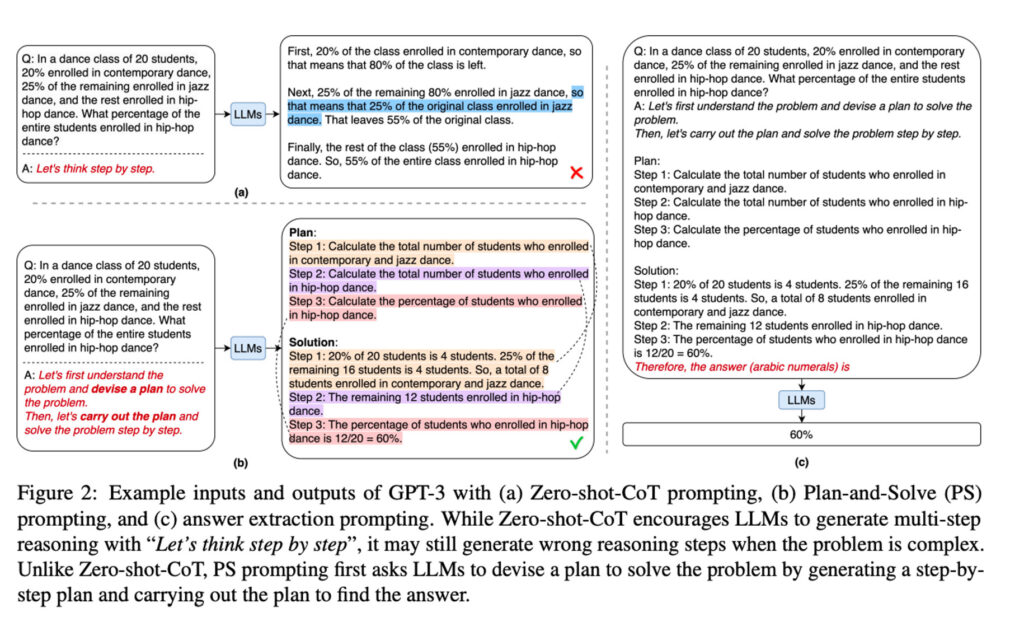
Plan-and-Solve는 복잡한 문제를 풀기 위한 순차적인 계획을 세우고 이를 하나씩 실행하여 문제를 해결하는 방법입니다. 아래 그림에서 볼 수 있듯이, 먼저 사용자의 질문에 답변하기 위한 계획을 한 번에 세우고(Step 1, Step2, Step 3) 그 계획을 하나하나 실행한 결과를 종합하여 최종 답변을 만들어냅니다.
반면 Self-Ask는 복잡한 문제를 풀기 위한 계획을 한 번에 다 세우는 것이 아니라 현 시점에서 수행해야 할 하나의 태스크만을 도출합니다. 그리고 매 스텝마다 현재까지의 정보를 종합하여 사용자의 최초 쿼리에 답변할 수 있는지 여부를 체크합니다. 만약 답변할 수 있다고 판단되면, 지금까지의 질의응답 맥락을 바탕으로 최종 답변을 내놓습니다. 하지만 만약 특정 정보가 부족하다고 판단되면, 해당 정보를 얻기 위해 수행되어야 할 다음 태스크를 도출합니다.

직관적으로는 두 방식 중 무엇이 더 우월한 방식인지 판단하기가 어려웠습니다. 결국 직접 케이스를 살펴보며 감을 익혀야겠다는 생각이 들어 빠르게 간단한 PoC 데모 페이지를 만들어 사내에 배포했습니다. 당시 라이너 팀원들이 많은 관심을 가지고 다양한 질문을 남겨주신 덕분에, 두 방식의 장단점을 파악해볼 수 있었고 나아가 어떤 종류의 질문에 답변을 잘해주는지 살펴보며 킬러 유즈 케이스들도 몇 가지 발굴해낼 수 있었습니다.
저희가 관찰한 사실을 간단히 공유드리면, Self-Ask의 경우 한 번 잘못된 길로 빠지게 되면 태스크가 종료되지 못하고 계속해서 다음 태스크를 생성하는 사례가 존재했습니다. 이는 서비스 관점에서 사용자로 하여금 태스크가 언제 끝날지 모르게 만든다는 점에 있어 큰 단점일 뿐만 아니라, 비용적으로도 문제가 됩니다. Plan-and-Solve의 경우엔 플랜을 중간에 수정할 수 없기 때문에 최종 답변의 퀄리티가 최초 생성한 플랜에 많이 의존하는 경향을 보였습니다. 다만 저희는 Plan-and-Solve 방식의 제어권이 상대적으로 저희 쪽에 있고, 추후 우선 순위 조정이나 태스크 수정 등 프로세스를 붙여나가며 한계점을 보완할 수 있을 것이라 판단하여 두 방식 중 Plan-and-Solve 방식으로 Autonomous Agent의 Planning 컴포넌트를 구현하기로 결정했습니다.
LINER Autonomous Agent
이제 LINER Autonomous Agent의 구조를 하나하나씩 뜯어 소개해드리겠습니다. 전체적인 구조는 아래 그림과 같은데요. AnswerTypeDecider, TodoMaker, SubTaskExecutor, FinalAnswerCompleter 4가지 주요 컴포넌트가 존재합니다.
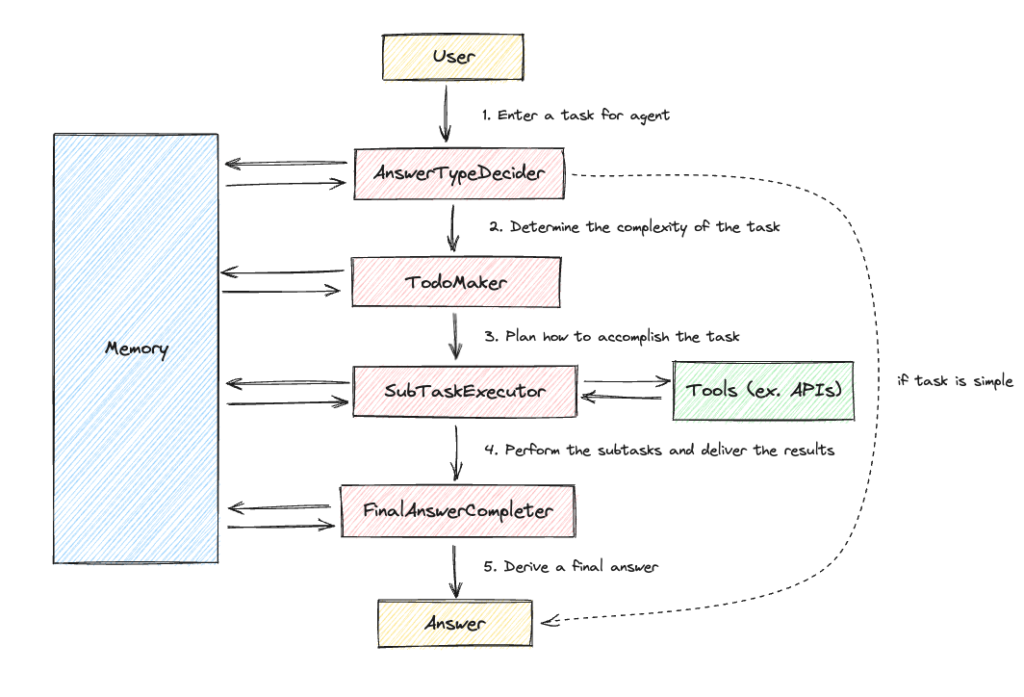
1. AnswerTypeDecider
사용자가 워크스페이스에서 특정 쿼리를 입력하면, Autonomous Agent는 가장 먼저 쿼리의 복잡도를 분석해서 (1) 한 번에 답변할지, (2) 쿼리를 작은 서브 태스크들로 쪼개어 이들을 순차적으로 수행한 결과를 종합하여 답변할지를 결정합니다. 한 번에 답변할 수 있는 쿼리라고 판단되면 굳이 서브 태스크들을 만들지 않습니다. AnswerTypeDecider는 Agent의 최초 퍼널이자 이후 프로세스가 결정되는 부분이기 때문에, 어찌보면 앞서 설명드린 Planning처럼 LLM의 높은 추론 능력을 필요로 하는 중요한 단계입니다.
저희는 CoT, ReAct 등의 기법을 통해 LLM이 어떤 의사결정을 내리기 전 Reasoning을 거치면 더 나은 답변을 뱉는다는 사실을 알게 되어, 복잡한 쿼리인지 여부를 결정하기 전에 그렇게 판단한 이유를 먼저 제시하도록 LLM에게 요청했습니다. 그 결과, 쿼리의 복잡도만을 판단하도록 했을 때보다 더 일관성 있는 답변이 나오는 것을 확인할 수 있었습니다.
또한 라이너 워크스페이스에서 사용자들은 이전 쿼리-답변 맥락에 이어서 멀티턴으로 질문을 할 수 있기 때문에 (ex. “위 답변 간단히 요약해줘” ), 이전 쿼리-답변 히스토리를 프롬프트에 함께 넣어주고 이를 고려하여 쿼리의 복잡도를 판단하도록 요청했습니다.
`Your job is to look at the user's query and decide how to accomplish the task.`,
...
`You have two choices, A and B.`,
...
`Your output should be a JSON object with the following format:`,
`{`,
` "reason": str,`,
` "type": "A" | "B"`,
`}`,
...
2. TodoMaker
TodoMaker는 앞서 설명드린 Planning 컴포넌트의 역할을 수행합니다. AnswerTypeDecider에서 사용자의 쿼리가 복잡한 쿼리라고 판단되면, TodoMaker에서는 Plan-and-Solve 방식을 이용해 사용자의 요청사항을 수행하기 위한 여러 개의 서브 태스크를 만들어냅니다.
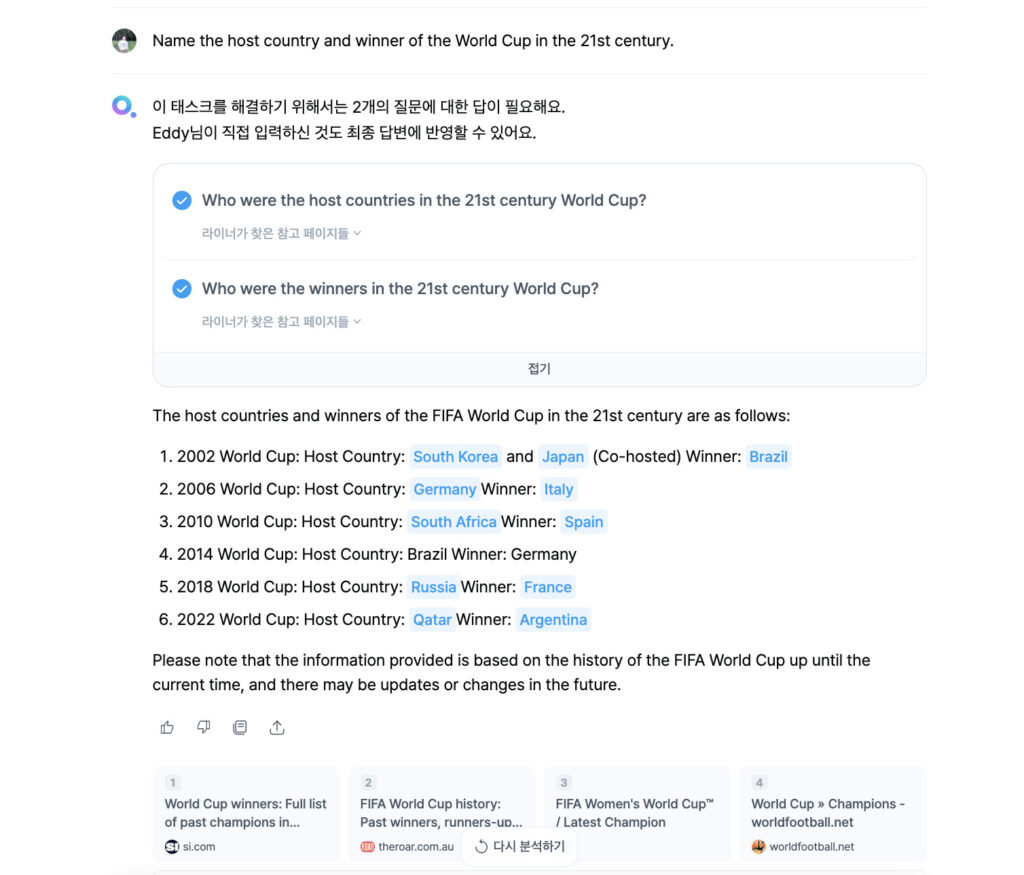
TodoMaker에서 한 가지 특별한 부분은 바로 서브 태스크 간의 의존성을 나타내는 dependency입니다. 어떤 서브 태스크의 경우 이전에 수행되었던 서브 태스크 결과를 알아야 더 잘 수행될 수 있는 경우가 있습니다. 예를 들어 “2022 카타르 월드컵에서 우승한 국가의 주장은 누구였어?” 라는 질문에 답하기 위해선 2022 카타르 월드컵의 우승국이 어딘지를 먼저 검색하고, 그 후에 해당 국가의 주장이 어떤 선수였는지를 파악해야 합니다.
하지만 그렇다고 이전 모든 태스크의 수행 결과를 프롬프트에 넣어주게 되면 불필요하게 Input Token 수가 늘어나 비용이 많이 발생합니다. 따라서 서브 태스크 간의 의존 관계를 명시해둔 dependency를 도입함으로써 의존성이 걸려있는 태스크의 수행 결과만을 맥락으로 넣어주었고 Input Token 길이를 줄일 수 있었습니다. 그리고 서로 의존 관계가 없는, 독립적인 서브 태스크끼리는 병렬적으로 수행되도록 하여 전체 태스크 수행 시간을 단축할 수 있었습니다.
`Your task is to decompose the question into a series of subqueries.`,
...
`The output should be a list of JSON object in the following format:`,
`[{"id": int, "query": str, "dependency": [id, ...]}, ...]`,
...
`The dependency is a list of ids that the current task depends on.`,
...
3. SubTaskExecutor
SubTaskExecutor는 Autonomous Agent가 상황에 맞게 필요한 도구를 자체적으로 선택하여 각각의 서브 태스크들을 수행하는 단계입니다. LLM은 아주 똑똑한 지능을 가지고 있지만 학습에 활용되지 않은 정보에 대해서는 답변을 잘 하지 못하는 한계가 존재합니다. 따라서 이런 경우 외부 API를 도구로 활용하여 부족한 부분을 메꾸고 확장성을 높일 수 있습니다. 예를 들어 Autonomous Agent가 최신 정보를 필요로 하는 서브 태스크를 수행해야 할 때, 검색 API라는 도구를 이용해 최신 정보를 먼저 검색하고 그에 기반하여 신뢰할 수 있는 답변을 내놓을 수 있습니다. 또 캘린더 API를 이용하면 Autonomous Agent가 사용자의 스케줄을 이해하고 비어 있는 시간대에 새로운 일정을 등록할 수도 있습니다.
LLM이 가지고 있는 Internal Knowledge도 하나의 도구로써 이용할 수 있습니다. LLM은 이미 웹 상의 방대한 데이터로 학습되어 똑똑한 지능을 가지고 있기 때문에, 때로는 검색을 거치는 것보다 LLM의 자체 지식으로 답변하는 것이 더 빠르고 효율적입니다. 프로그래밍이나 번역 같은 태스크가 LLM의 자체 지식을 활용하면 좋은 대표적인 태스크라고 볼 수 있습니다.
저희는 SubTaskExecutor가 실행되는 모든 과정에서 LLM의 지능을 전적으로 활용했습니다. 여러 도구 중 어느 도구를 선택하여 서브 태스크를 수행할지부터, 검색 API를 이용할 경우 LLM에게 적절한 검색어를 생성하도록 하였고, 맥락 정보로 넣어주는 이전 서브 태스크 수행 히스토리가 길어 요약이 필요한 경우에도 LLM을 활용했습니다.
각 서브 태스크의 수행 결과는 메모리에 저장해두고 의존성이 걸린 다음 서브 태스크 수행 시 불러와 맥락 정보로 넣어주었습니다.
`Your task is to generate a list of search engine queries.`,
...
`The output must be a list of queries in the format: [Query 1, Query 2, ...]`,
...
`Create search queries based on a given context.`,
...
4. FinalAnswerCompleter
FinalAnswerCompleter에서는 이전에 수행된 서브 태스크들의 맥락을 잘 종합하여 최종 답변을 도출합니다. LLM은 Context Length가 제한되어 있기 때문에, 서브 태스크 히스토리가 긴 경우에는 상황에 따라 Context Length가 긴 모델을 선택하여 사용하거나 히스토리를 요약해서 맥락 정보로 넣어주었습니다.
`Your task is to understand the context from the conversation history and generate an informative answer to the given query based on your understanding.`,
...
`A given conversation history may contain information not relevant to your question, so make sure to pull in only the information you think you need to generate your report.`,
...
Evaluation & Use Cases
지금까지 라이너 워크스페이스에 도입된 Autonomous Agent에 대한 기술적 설명을 드렸습니다. Autonomous Agent가 서비스에 배포된 후 팀 내외부적으로 “진짜 LINER Agent가 다른 LLM 프로덕트에 비해 잘해? 얼마나 잘하는데?” 라는 질문을 종종 받곤 했는데요. 저희는 Autonomous Agent를 앞으로 관리하고 개선해나가기 위해 성능을 정량적으로 측정하는 것이 무엇보다 중요하다고 생각했습니다. 그래서 Agent Evaluation System을 구축하여 ChatGPT, GPT-4와 성능 비교를 진행했고, 정보 탐색 측면에서 LINER Agent가 더 나은 성능을 보임을 확인할 수 있었습니다. 해당 Evaluation 과정에 대해서는 추후 별도의 블로그 글을 통해 소개드리려고 합니다.
현재 라이너 워크스페이스에서는 전 세계의 사용자들이 수많은 태스크를 요청하고 Autonomous Agent로부터 가치를 얻어가고 있습니다. 매일 사용자들이 입력하는 다양한 종류의 쿼리 중 저희가 판단하기로 Autonomous Agent가 특히 잘 해내는 케이스 몇 가지는 다음과 같습니다.
1. 한 번에 검색하기 어려운 복잡한 정보를 탐색해야 할 때: Name the host country and winner of the World Cup in the 21st century.
2. 웹 사이트 링크를 받아보고 싶거나, 답변의 근거 문서를 알고 싶을 때: Recommend me some blog posts about Large Language Model-based Autonomous Agent.
3. 두 가지 이상의 대상을 비교하거나, 일반적인 주제에 관한 리포트를 작성하고 싶을 때: Make a short report of world economy.
Future Work
Autonomous Agent를 도입하며 라이너는 ‘Help People Get More Done with Less Time & Energy’ 라는 목표를 향해 한 발짝 나아갈 수 있었습니다. 하지만 아직 개선의 여지 또한 많이 남아있으며, 앞으로 저희가 집중할 영역은 아래와 같습니다.
먼저 Task Planning과 Refining 로직을 고도화해보려고 합니다. 현재 Autonomous Agent의 경우 최초 플랜을 잘못 세웠을 때 최종 답변의 퀄리티가 낮아지거나, 서브 태스크를 수행하다보면 최초 쿼리와의 Alignment가 조금씩 벗어나는 경우가 존재합니다. 이를 보완하기 위해 태스크 수행 전후에 Observation (Reflection) 단계를 추가하여 현재 태스크 수행 상황을 되돌아보고 플랜을 수정하는 방안을 떠올려볼 수 있습니다.
Autonomous Agent PoC 데모로 잘 알려진 AutoGPT, BabyAGI, AgentGPT 역시 이러한 Observation을 추가하여 중간중간 새로운 서브 태스크를 만들고 우선 순위를 조정하는 구조를 가지고 있습니다. 저희도 이와 같이 Plan-and-Solve와 Self-Ask의 장점을 적절히 잘 조합하는 방향으로 Agent를 개선해나갈 예정입니다.
다음으로 Autonomous Agent에 쥐어줄 수 있는 도구를 더 다양하게 구성해보려고 합니다. 지금까지는 정보 탐색이 LINER Agent의 주 목적이었기 때문에 검색 API 같은 도구를 Agent에 우선적으로 붙였는데요. 앞으로는 구글 캘린더, 뉴스, 날씨, 지도 API등 생산성을 위한 도구들을 붙이며 개인의 능률을 향상시키기 위한 워크스페이스로 더욱 진화해나갈 예정입니다.
이외에도 비용 감축을 위해 Open Source LLM이나 Fine-tuning 모델을 활용하는 것, 정밀한 Evaluation을 통해 현재 Agent의 성능을 측정하고 기능을 개선해나가는 작업 등도 저희가 챙겨야 할 요소입니다.
마치며
라이너 팀은 사용자들이 진짜로 ‘잘 쓰는’ LLM 기반의 제품을 만들어나가고 있습니다. 그 과정에서 저희 머신러닝 엔지니어들은 새로운 아이디어를 내고, 생각한 바를 구현하고, 가설을 검증하는 전 과정에 기여하며 함께 성장하고 있습니다. LLM 관련 최신 연구 및 시장 동향을 파악하고 제품에 빠르게 적용해볼 수 있는 것도 라이너 머신러닝 플래닛만의 매력 중 하나입니다.
글을 읽으며 LINER의 Autonomous Agent에 대한 흥미가 생기셨나요? 저희와 함께 문제를 해결하면서 성장하고자 하시는 분이 있다면 언제든지 연락주시면 감사하겠습니다. 앞으로도 라이너에 많은 관심과 응원 부탁드리며, 블로그를 통해 다음에 소개드릴 이야기도 기대해주세요😀