콜드 스타트 유저에게 콘텐츠 추천하는 방법 – 트렌드 기반 추천
안녕하세요, 머신러닝 엔지니어 카터입니다. 지난 몇 편의 글들을 통해 라이너가 개인화 콘텐츠 추천을 위해 어떤 방향으로 기술을 발전시켜 나가고 있는지에 대한 소개를 드릴 기회가 있었습니다. 하지만 프로덕트에 적용되는 추천 기술을 개발한다는 의미가 단순히 “로그 데이터가 충분히 쌓여, 개인화 추천에 용이해진 사용자들의 경험”만 챙기겠다는데에 그치는 것은 아닙니다.
플랫폼에 이제 막 진입해 인터랙션 히스토리가 전혀 존재하지 않는 신규 사용자들에게도 콘텐츠 추천의 경험을 제공해야 하기 때문인데요. 해당 문제는 이 글을 읽고 계신 많은 분들이 알고 계시듯 “Cold-start User/Item Problem” 이라 불리며, 이를 해결하기 위해 다양한 방식의 연구들이 진행되고 있습니다. 혹은 제품 내 UX를 통해 문제를 우회하는 방법들도 존재합니다.
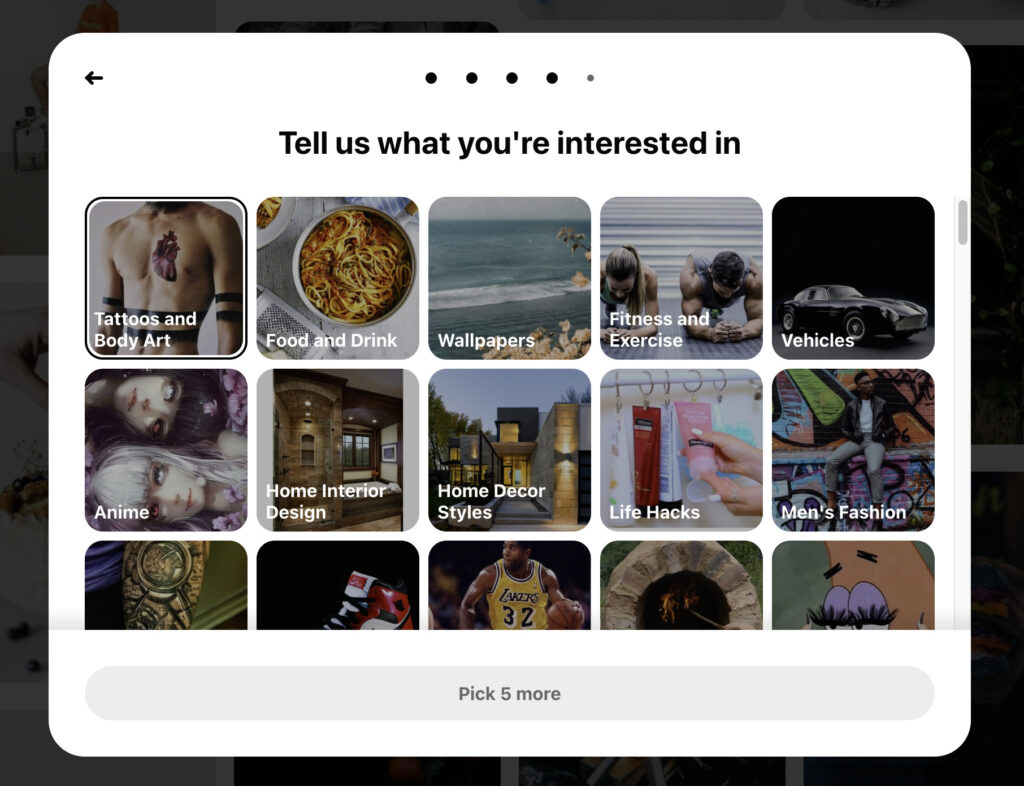
그 중 가장 대표적인 안으로는 신규 가입 사용자에게 가입 과정 중 “관심사” 등 사용자 선호 정보를 입력하도록 유도해 선호 정보를 추천의 시드(Seed)로 활용하게 되는 선호 정보 기반 추천이 있습니다. 뛰어난 개인화 추천으로 널리 알려진 Pinterest 역시 온보딩 과정 중, 관심사를 선택하는 스텝을 추가해 사용자 선호 정보를 최대한 Explicit 하게 수집하고 있죠.
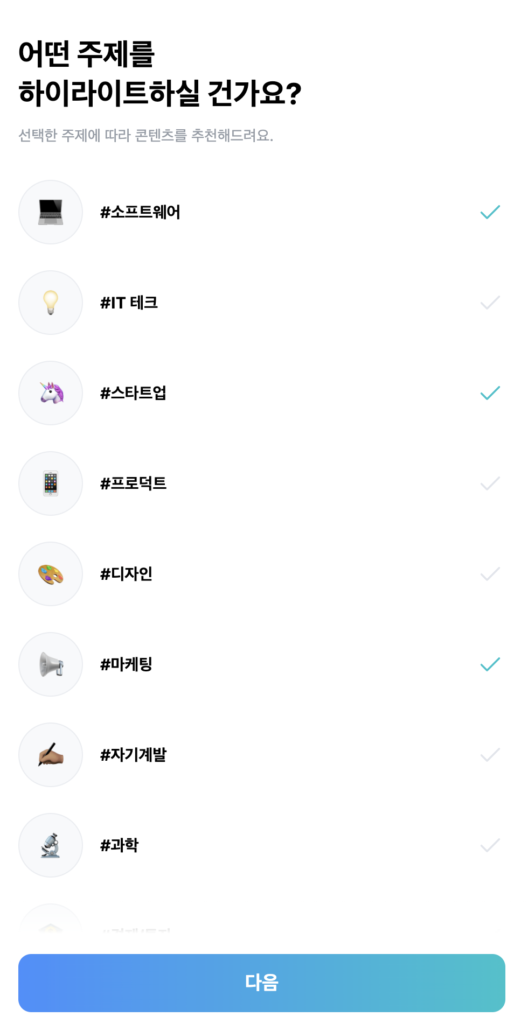
라이너 역시 Pinterest와 유사하게 Cold-start User 문제를 관심사 정보를 통해 일부 해결하고 있습니다. 신규 가입자에게 온보딩 과정 중 관심사 선택을 유도 후, 아래 그림과 같이 관심사에 기반해 콘텐츠를 받아볼 수 있도록 문제를 정의한 셈인데요. 하이라이트를 통해 적재되는 콘텐츠를 특정 관심사로 어떻게 매핑시킬 수 있었는지에 대해서는 다음에 기회가 된다면 포스트를 통해 소개해보도록 하겠습니다.
사용자로부터 Explicit 하게 수집한 관심사 정보를 활용해, 플랫폼 최초 진입 시점부터 사용자 선호 정보가 반영된 콘텐츠를 추천해주는 아이디어는 간단하고도 바로 적용하기 좋은 안입니다. 그러나 저희는 라이너에 실시간으로 적재되는 하이라이트 데이터를 십분 활용해 현재 라이너를 사용하는 다른 사용자들은 어떤 글에 하이라이트하고 있는지 등의 인사이트가 녹아든 추천 경험을 제공하고 싶다는 생각을 하게 되었고, 그렇게 하이라이트 인터랙션 기반 트렌딩 콘텐츠 추천을 제공하기로 결정했습니다.
트렌드 기반 추천
사실 라이너에 트렌드 기반 추천이 고려된 적이 이번이 처음은 아닙니다. 기존에도 개인화를 위한 인터랙션이 없는 Cold-start User 에게 트렌드 기반 추천과 비슷한 경험을 제공해주고 있었습니다. 바로 다른 사용자가 “공개” 상태로 하이라이트를 저장한 경우, 하이라이트의 대상이 되었던 문서를 신규 사용자들에게 노출시켜주었던 기능이 트렌드 기반 추천과 유사한 가치를 기대하며 과거 배포한 기능입니다.
즉, 여러분들이 지금 보고 계신 이 글에 바로 하이라이트를 하게 될 경우, 때마침 “이 시점에 라이너 제품에 온보드 된 사용자”에게 이 글이 추천되는 방식이었죠. 눈치채셨겠지만 이는 트렌드 기반 추천이라기 보다, 최신순 추천에 가까울 수 있겠습니다. 따라서 해당 로직을 실제 우리가 보편적으로 이해하고 있는 “트렌드” 기반의 추천으로 개선하기 위한 작업을 수행했습니다.
트렌드 기반의 추천을 수행하기 위해서는 추천되는 문서가 "트렌딩"하다는 성질을 지녀야 합니다. 따라서 과거에 특정 문서가 A 정도의 관심을 받았지만, 최근 A를 넘어 B 정도의 관심을 받아야만 해당 문서를 트렌딩하다고 규정할 수 있습니다. 혹은 최근 업로드 되어 과거 로그 스트림에는 등장하지 않았지만, 갑자기 많은 관심을 받기 시작한 문서 역시 트렌딩으로 규정할 수 있습니다. 라이너는 현재 이러한 특성을 담은 스코어를 계산하기 위해, 아래와 같은 식을 활용합니다.

트렌딩 스코어라고 부르고 있는 위 스코어는 다음과 같이 계산됩니다.
- 특정 문서에 대해 버킷을 두어 최근 90일 이내 하이라이트 된 횟수, 최근 60일 이내 하이라이트 된 횟수, …, 최근 6시간 이내 하이라이트 된 횟수 등 피쳐로 활용할 값을 추출합니다.
- 수식의 분모는 1번 과정에서 추출한 모든 값들의 합이 됩니다.
- 수식의 분자는 (w_1 x 최근 6시간 이내 하이라이트 된 횟수 + … + w_n-1 x 최근 60일 이내 하이라이트 된 횟수 + w_n x 최근 90일 이내 하이라이트 된 횟수)가 됩니다.
- w_n은 각 피쳐 값에 곱해지는 가중치 변수이며, 당연하게도 최신에 해당하는 값들에 대해 더 높은 가중치가 부여됩니다.
위 과정을 통해 구해진 트렌딩 스코어를 내림차순 정렬 후, 라이너에서 생산적인 콘텐츠로 분류하고 있는 콘텐츠들을 최종적으로 트렌딩 콘텐츠로 선정해 사용자들에게 반환하게 됩니다.
국가별 트렌드 추천
위 과정을 적용하는 것만으로도 기존에 제공하던 최신순 정렬 콘텐츠 추천이 아닌 “트렌딩” 콘텐츠 추천의 경험을 사용자에게 제공할 수 있게 되었습니다. 그러나 아직 한 가지 아쉬운 점이 있었습니다. 시간대에 따라 특정 국가의 로그가 트렌딩 추천 콘텐츠 형성에 크게 영향을 미칠 수 있다는 점이었습니다.
라이너는 미국, 영국, 호주, 인도 등 서로 다른 대륙에 거주한 사용자들이 사용하는 글로벌 서비스입니다. 따라서 최신성에 가중치를 크게 부여하는 트렌딩 스코어 수식에 따르면, (UTC를 기준으로 했을 때) 시간대 별로 특정 국가 사용자들이 트렌딩 콘텐츠 형성 작업에 미치는 영향도가 커질 수 있다는 문제가 제기된 것입니다. 한국 시간으로 밤에 작업이 실행될 경우, 한창 낮시간대인 국가의 로그가 영향도가 커지겠죠. 따라서 야밤에 라이너에 랜딩한 신규 한국 가입자들은 난데 없는 콘텐츠를 마주하게 될 확률이 매우 높아집니다.
위 문제를 해결하기 위해 국가별로 트렌딩 콘텐츠 형성 작업을 달리 가져가는 방식을 적용했습니다. 즉, 하이라이트 로그를 국가 코드 기준으로 그루핑 해 트렌딩 스코어를 계산하도록 합니다. 국가별로 스코어를 따로 계산하므로, 계산된 결과는 특정 국가에 종속되기 때문에 국가별 트렌딩 콘텐츠 리스트가 반환될 것입니다. 따라서 해당 콘텐츠 리스트를 Cloud Storage에 적재해 요청 사용자 국가에 따라 대응하는 결과 값을 반환하도록 합니다.
이처럼 국가별로 트렌딩 콘텐츠를 달리 계산 및 추출하는 로직을 통해, 한국 신규 사용자의 경우 한국 사용자들의 하이라이트 로그만으로 형성된 콘텐츠 리스트를 받아볼 수 있게 되었습니다. 이는 사용자와 콘텐츠의 정합성을 맞추어 주었을 뿐만 아니라, 지역성 측면에서 사용자에게 보다 연관 있는 추천을 제공해주기도 하게 됩니다.
라이너는 최종적으로 “국가별 트렌드 콘텐츠 추천 로직”을 서비스에 적용하기로 결정하였습니다. 트렌드 콘텐츠를 주기적으로 구워주는 작업은 Airflow를 통해 진행되고 있으며, 배치 작업이 BigQuery에 적재된 하이라이트 로그를 활용해 트렌딩 스코어를 계산 후 특정 Threshold 이상의 콘텐츠들을 대상으로 적재를 하게 됩니다.
사용자의 트렌딩 콘텐츠 추천 요청은 국가별로 캐시가 적용되어, 최초 요청자의 요청 이후 온보드 된 사용자들에게는 캐시에서 콘텐츠 리스트를 받아와 반환해주게 됩니다. 최초 요청자의 경우, 앞서 배치 작업을 통해 Cloud Storage에 적재된 국가별 트렌딩 콘텐츠 JSON 파일을 읽어와 반환해줍니다.
마치며..
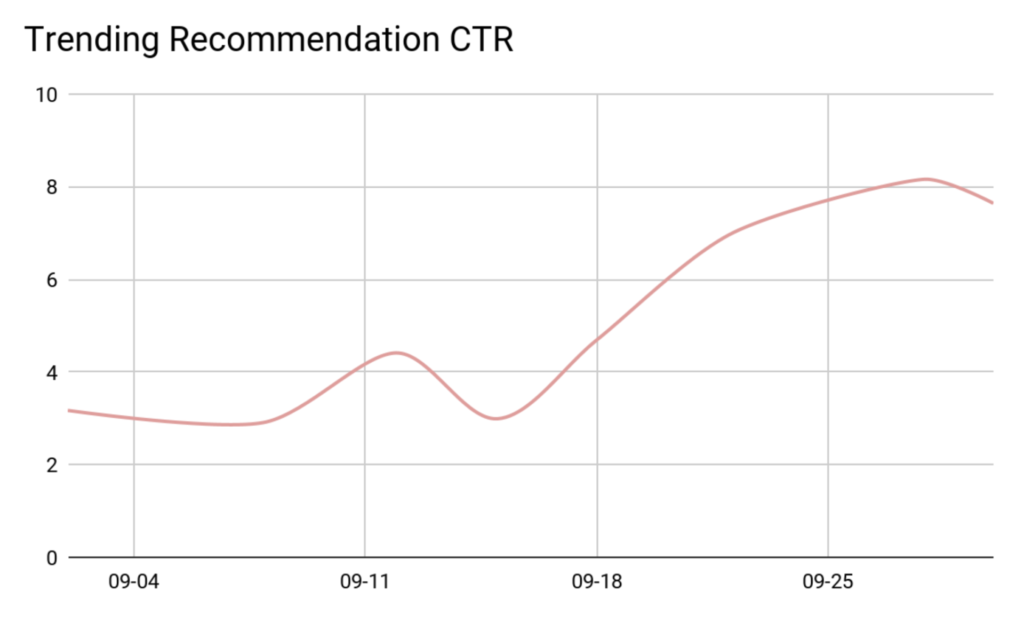
과연 적용 결과는 어땠을까요? 실제로 글을 통해 소개해드린 트렌드 기반 콘텐츠 로직을 배포 후, 관련 추천 CTR이 크게 개선되었습니다. 최신순 콘텐츠 추천은 한 사람의 피드백이 반영된 반면, 트렌드 기반 콘텐츠 추천의 경우 여러 사람의 피드백이 함께 반영되기 때문에 보다 많은 사용자들의 흥미를 돋게 되었을 것이라 해석하고 있습니다.
트렌드 기반 추천 로직 개선은 여기서 그치지 않습니다! 4분기에는 트렌딩 콘텐츠 중에서도 신규 사용자가 보다 더 많은 관심을 가질만한 콘텐츠 순으로 줄을 잘 더 세워 반환하려는 시도를 해보고자 합니다. 사용자 인터랙션이 없는 페이즈이기 때문에, 앞서 소개드린 관심사 정보를 활용해 관심사 벡터를 형성해 활용해보지 않을까 생각하고 있습니다.
라이너 구성원들은 “Help People Get Smart Faster” 라는 미션을 달성하기 위해 모였습니다. 그 중 머신러닝 조직은 기술을 통해 사용자들이 생산적인 정보를 소비 및 수집할 수 있도록 돕고, 그 이력을 시드 데이터로 활용해 개인이 더 성장하기 위해서는 어떤 콘텐츠를 추가적으로 소비하면 좋을지 알려주는 추천과 탐색의 영역을 책임지고 있습니다.
때문에 사용자 선호를 보다 더 잘 파악하기 위해 사용자가 “최대한 빠른 시일 내에 콘텐츠를 수집”할 수 있도록 도와야하기도 합니다. 그리고 그 과정에 있어 Cold-start User Problem 을 해결하야 하는 필요성이 대두되게 됩니다. 현재는 글을 통해 소개해드린 트렌드 기반 추천과 관심사 기반 추천을 통해 문제를 일부 해결하고 있습니다만, 더 나은 방안은 항상 존재한다고 굳게 믿고 있습니다.
그리하여 결론은.. 사용자들이 더 똑똑한 방향으로 나아갈 수 있도록 돕는 라이너의 여정에 기술적 기여를 해주실 분들을 기다리고 있습니다 🙂