토픽 모델링으로 그리게 될 LINER의 미래
안녕하세요, 머신러닝 엔지니어 카터입니다. 지난 글에서는 라이너의 컨텐츠 기반 필터링 모듈 구축기에 대한 소개를 드렸습니다. 이번 글에서는 현재 라이너가 토픽 모델링을 어떻게 활용하고 있으며, 앞으로의 라이너 기술 발전 방향에 있어 토픽 모델링이 왜 중요한지에 대한 소개를 드리고자 합니다!
토픽 모델링이란 ?
“라이너 ❤️ 토픽 모델링” 이야기에 앞서 토픽 모델링이란 무엇인가부터 짚고 넘어가보도록 하겠습니다. 위키피디아에서는 토픽 모델을 다음과 같이 정의하고 있습니다.
In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents.
Wikipedia – Topic Model
위 정의를 번역해보자면 토픽 모델은 다량의 문서 집합에서 발생한 추상적 토픽을 발굴하는 통계 모델입니다. 여기서 주목해야 할 키워드는 “다량의 문서”와 “추상적 토픽”입니다. 즉, 토픽 모델은 비정형 데이터인 텍스트로 작성된 (다량의) 문서에 대해, 통계적 방법론을 활용해 사람이 이해할 수 있는 토픽을 부착하는 기술입니다. 따라서 토픽 모델링은 토픽 모델을 학습하고, 문서 집합에 대해 토픽을 부착하는 일련의 과정을 총칭하게 됩니다.
토픽 모델링을 잘 활용하게 되면 서비스를 통해 적재되는 대량의 문서 집합에 대해 사람의 손을 빌리지 않고도, 유의미한 정보를 손쉽게 부착할 수 있습니다. 때문에 많은 양의 컨텐츠를 다루어야 하는 서비스 조직에서 토픽 모델링을 잘 활용하는 것은 매우 중요한 과제입니다.

전통적인 토픽 모델링은 대부분 BoW 기반의 LDA를 통해 이루어졌습니다. 그러던 2017-18년 GPT, ELMo, BERT의 연단 등장으로, 자연어 처리 도메인 내 모든 태스크에서 Contextualized Language Model 을 적용했을 때 성능 향상을 관측할 수 있었습니다. 물론 토픽 모델도 예외는 아니었습니다.
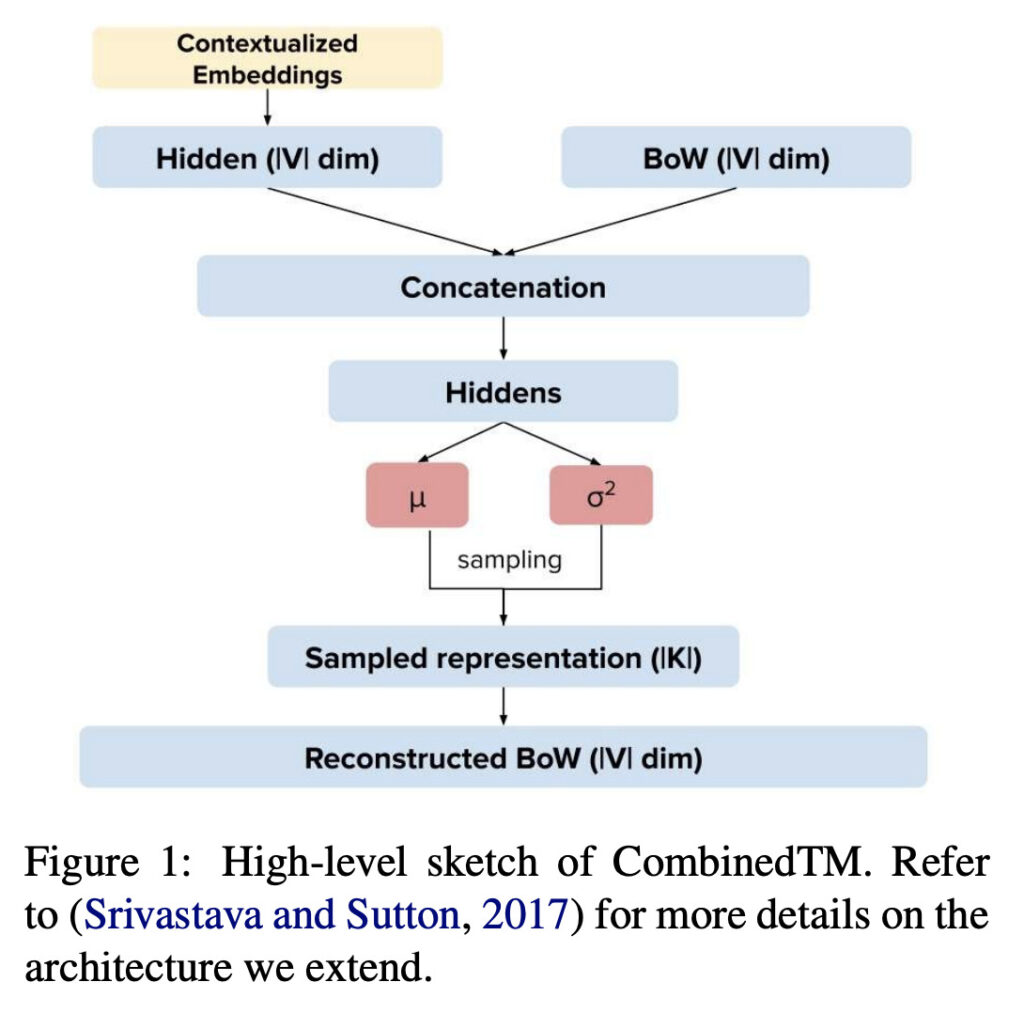
concat 하여 학습에 활용하는 CombinedTM2021년 ACL에 기재된 Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence에서는 일반적인 토픽 모델링을 위해 활용되는 BoW (Bag-of-Words) 벡터에 PLM을 통해 문서를 임베딩 한 벡터를 concat하여 학습에 활용하면 토픽이 더 일관되게 잘 추출된다는 결과를 공개했습니다. 해당 논문은 토픽 모델 구조로 Variational Autoencoder 기반의 ProdLDA를 채택하였습니다.
이후 같은 해, EACL을 통해 동일한 연구진들이 Cross-lingual Contextualized Topic Models with Zero-shot Learning 논문을 통해 Contextualized Representation 을 추출하는 언어 모델로 Multilingual 모델을 활용하면 Zero-shot으로 다른 언어로 작성된 문서에 대해서도 토픽을 추론할 수 있음을 밝혔습니다. 그 과정은 다음과 같습니다.
먼저, 하나의 언어 (논문에서는 영어)로 작성된 문서들로만 토픽 모델을 학습합니다. 이때는 BoW 벡터와 Contextualized Representation 이 모두 학습에 활용됩니다. 이후, 학습된 모델로 하여금 다른 언어로 작성된 문서에 대해 토픽을 추론하도록 합니다. 이때는 당연하게도 BoW 벡터를 활용할 수 없기에 Contextualized Representation 만 활용하게 됩니다.

토픽 모델링의 개념에 이어 Contextualized Representation 을 활용한 두 논문에 대해 공유드린 이유는 라이너가 나아가고자 하는 방향과 논문의 방향성이 굉장히 부합하기 때문입니다. 또한 저자진들이 깃헙을 통해 연구 관련 소스 코드를 활발히 공유 및 유지 보수해주고 있어, 실험도 손쉽게 진행할 수 있다고 판단하여 해당 논문을 라이너 토픽 모델링 실험의 방향성으로 선정하게 되었습니다.
* 지금부터 라이너 토픽 모델을 CTM (Combined TM)이라 칭하고 글을 이어나가도록 하겠습니다.
LINER Topic Modeling – 현재
본 섹션에서는 앞서 소개드린 CTM 학습 과정과 적용 사례에 대해 설명드리겠습니다. 우선 21년 1월부터 텍스트 하이라이트 액션이 발생한 모든 텍스트 문서를 수집하였습니다. 이후, 언어 감지를 통해 언어가 영어로 감지된 문서에 대해 CTM 학습을 진행하였습니다. 참고로 현재 라이너는 언어 감지를 위해 fastText를 활용하고 있으며, 학습 관련 예제는 CTM 깃헙에 잘 소개되고 있으니 참고 부탁드립니다.
학습에 있어 주의해야 할 사항이 몇 가지 있는데, CTM 내부적으로 BoW 사전 구축을 위한 전처리기를 제공하지만, 공백 기반의 토큰화만 수행하도록 작성되어 있기 때문에 한국어와 같은 교착어는 전처리기를 직접 만들어 활용해야 합니다. 혹은 영어 전처리에 있어서도 spaCy를 활용하도록 변경할 수도 있습니다. 또한 불용어를 따로 설정하지 않으면, NLTK 불용어 사전을 활용하도록 되어있지만, 도메인 마다 처리해주어야 할 불용어가 다를 수 있기 때문에 불용어 커스터마이즈도 따로 진행하시는게 좋습니다.
사전 구축이 어떻게 되는지에 따라 토픽 모델의 결과도 크게 달라지기 때문에 전처리 로직 작성과 불용어 설정은 매우 신중히 해주시는게 좋습니다. 저 같은 경우 spaCy 토크나이저 변경 후 엔티티 처리 등 여러 로직을 추가해 실험을 해보았지만, 로직의 지나친 추가는 결국 전처리 시간의 증가로 이어졌고 시간 대비 결과의 개선을 크게 못느껴 최종적으로 spaCy 토크나이저 + 이메일, 숫자 등 제거 + 라이너 불용어 적용의 조합을 가지고 전처리를 수행하도록 하였습니다.
* 엔티티 처리란 복합 명사를 하나의 사전 엔트리로 치환하기 위해, 엔티티로 추론된 명사를 Machine Learning → machine_learning 와 같이 공백을 포함하지 않는 한 개 단어로 교정해주는 작업입니다. 해당 작업을 통해 machine_learning 과 같은 키워드가 사전에 등록되어 최종적으로 토픽별 분포를 파악할 수 있게 됩니다.
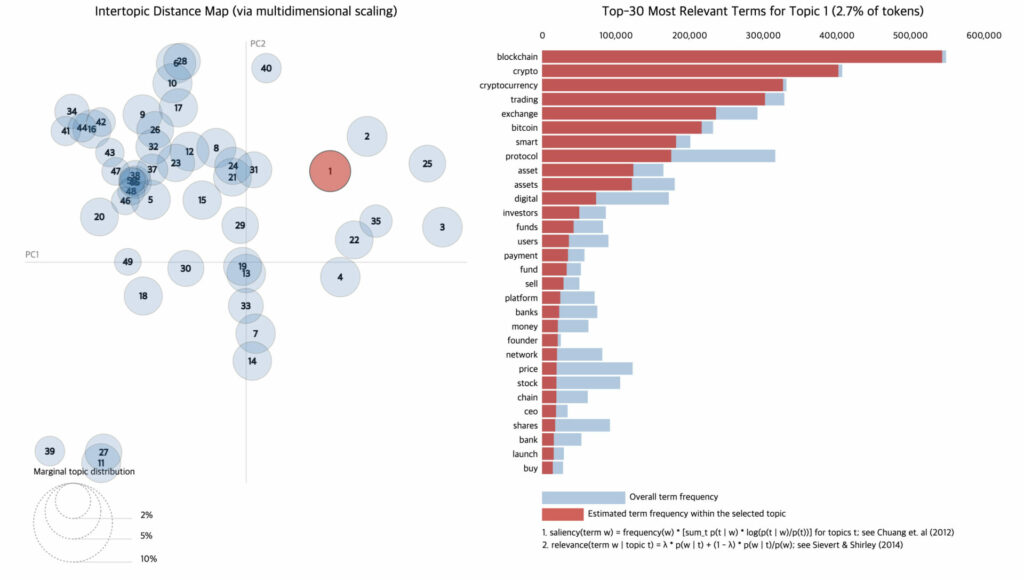
전처리 이후에는 사전 및 BoW 벡터 구축, Contextualized Embeddings 구축 등의 작업을 거쳐 토픽 모델을 학습하게 됩니다. 최종적으로 학습 이후에는 pyLDAvis를 통해 영롱한 토픽 맵을 얻을 수 있게 됩니다. 아무리 좋은 모델이더라도 학습에서 그친다면 빛 좋은 개살구가 되겠죠? 라이너가 토픽 모델링을 통해 어떠한 문제들에 태핑하고 있는지 소개드리겠습니다.

라이너는 (가입을 위한) 이메일을 제외한 사용자 정보를 전혀 받지 않기 때문에, 사용자 특성을 이해하기 위해 하이라이트 데이터를 이해하는 작업이 필요합니다. 따라서 라이너 사용자들이 발생시키는 하이라이트 데이터를 대상으로 어떠한 문서들이 라이너 플랫폼에 많이 적재되고 있고, 그 포션은 어떻게 구성되고 있는지 등을 파악하기 위해 토픽 모델링을 활용하고 있습니다.
특히 라이너에는 모든 팀원들이 자신이 작업을 진행하며 얻은 인사이트를 전사적으로 공유하는 문화가 매우 잘 조성되어 있는데요. 저 또한 토픽 모델링을 통해 얻은 라이너 플랫폼 인사이트를 전사적으로 공유하는 과정을 몇 차례 진행하였고, 이를 통해 라이너 사용자 군과 우리가 축적하고 있는 데이터에 대한 전사적인 이해가 많이 높아졌습니다.
다음으로 이번 글을 통해 설명드리기는 어렵지만, 지난 해부터 라이너는 내부 광고 플랫폼을 실험 중에 있습니다. 그리고 앞서 언급한 바와 같이 사용자 개인정보를 전혀 보유하지 않은 라이너가 사용자에게 맞춤 타겟팅을 하기 위해 토픽 모델링을 활용하는 방안을 고려하고 있습니다.
라이너는 사용자가 문서, 동영상 등에 대해 하이라이트한 데이터를 보유하고 있기 때문에 문서, 동영상 컨텐츠에서 토픽을 추출하는 방식으로 사용자 선호 토픽 기반 타겟팅 광고가 가능합니다. 또한 주로 학습을 위해 사용되는 텍스트 하이라이트와 달리 사용자의 개인 선호가 고르게 반영되는 동영상 하이라이트 덕분에 타겟팅 커버리지를 높일 수 있게 되었습니다. 광고와 관련해서도 하고 싶은 이야기가 많지만 주제를 벗어나므로, 다음에 광고 이야기로 꼭 돌아오도록 하겠습니다!

마지막은 예상 가능하게도 선호 토픽 기반 추천 엔진의 구축입니다. 개편 과정에서 잠시 사라지긴 했지만, 라이너에는 사용자가 선호 토픽을 설정할 수 있는 옵션이 있습니다. 사용자가 어떠한 컨텐츠에 관심을 가지는지 Explicit 하게 드러내는 해당 옵션은 사용자에게 컨텐츠를 추천함에 있어 Explainabililty 를 높이는데 큰 도움을 줄 수 있습니다.
즉, 당신이 “금융” 토픽에 관심을 보였기 때문에 A라는 컨텐츠가 추천되었다라는 맥락 있는 추천의 시나리오 뿐만 아니라 토픽별 트렌딩 컨텐츠 추천, 하이라이트 통계 (사용자 별로 어떤 토픽에 하이라이트를 많이 수행하였는지를 포트폴리오 형식으로 노출) 등 다양한 토픽 기반 피쳐를 고민하고 서비스에 녹여내려고 노력하고 있습니다.
LINER Topic Modeling – 미래
이전 섹션을 통해 느끼셨겠지만 라이너가 토픽 모델 기술의 발전을 통해 해결하고자 하는 문제는 명확합니다. 때문에 라이너가 겪는 토픽 모델링에 있어서의 어려움에 대해 간단히 소개드리며 글을 마치고자 합니다. 라이너 토픽 모델링의 첫 번째 어려움은 Domain Free 한 컨텐츠들에 대해 토픽 모델링을 수행해야 한다는 점입니다.
라이너에는 문자 그대로 세상 “모든” 컨텐츠가 적재될 수 있습니다. 때문에 전문 용어가 분절되어 사전에 등록되는데 어려움이 생긴다거나, 토픽 분포 학습을 해치는 컨텐츠가 적재된다거나 등 여러 어려움을 겪을 수 있는 환경에 있습니다. 이는 라이너에 적재되는 데이터를 지속적으로 정제하고 파악하는 과정에서 얻는 노하우로 해결해야한다고 생각하고 있습니다.
두 번째 어려움은 Contextualized Representation 을 활용한 토픽 모델링 방향성을 택하였기 때문에 임베딩 모델 성능에 토픽 모델 결과가 많이 좌우된다는 점입니다. 여러 실험을 통해 임베딩 모델의 변화가 토픽 모델 결과에 영향을 주는 것을 확인했습니다.
초기에는 Huggingface Hub에서 제공되는 Multilingual PLM을 활용하였지만, 이후부터 지금까지는 지난 글에서 공유드린 라이너 임베딩 모델을 활용하고 있습니다. 라이너 임베딩 모델이 세션 데이터를 통해 유사한 문서를 보며 학습되어 토픽 기반 클러스터링에 더 좋은 모습을 보이기 때문입니다. 앞으로도 좋은 임베딩 모델을 학습시켜, 토픽 모델 성능까지 개선할 수 있는 좋은 파이프를 구축하는 것을 목표로 하게 될 것 같습니다.
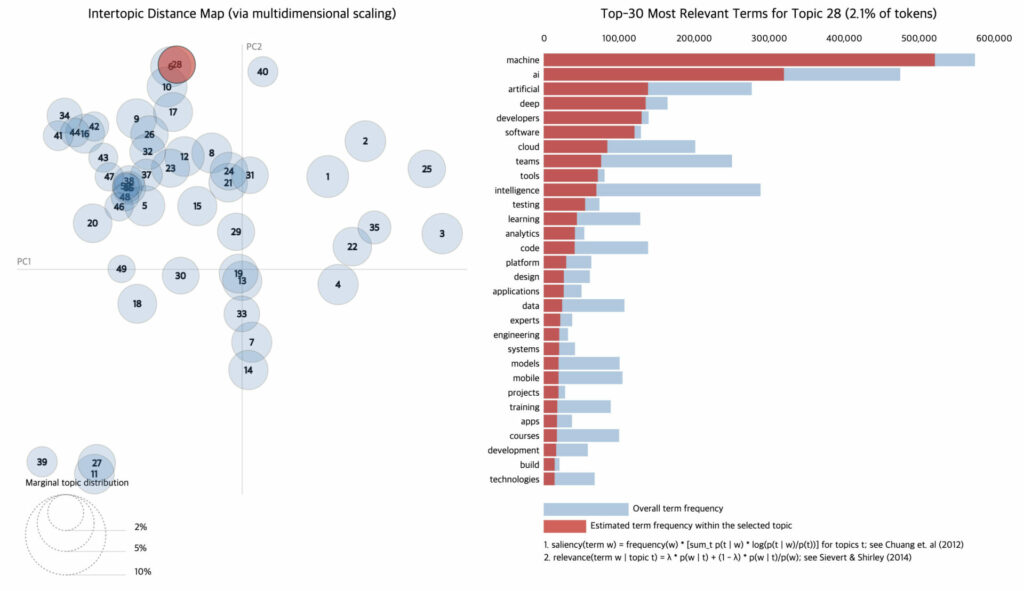

마지막으로 지속적으로 글을 통해 공유드린 바와 같이 라이너에는 여러 언어로 작성된 문서가 적재되고 있기 때문에 반드시 Multilingual 언어 모델로 토픽 모델을 성공시켜야 합니다. 이는 라이너가 토픽 모델로 CTM + Zero-shot의 방향성을 택하게 된 배경이기도 한데, 모든 언어에 대해 토픽을 구성할 사전을 구축하는 것은 매우 어려운 작업이기 때문입니다.
따라서 Contextualized Representation 의 힘을 믿고, 앵커 언어로 학습된 토픽 모델을 활용하는게 라이너가 나아가야 할 방향이라 생각하고 있으며, 이 역시 좋은 Mulitilingual 임베딩 모델을 학습하려는 목적을 달성하기 위해 노력하는 과정에서 사이드 이펙트로 해결되기를 기대하고 있습니다.
다음으로 어려움은 아니지만, 라이너가 토픽 모델에 집중하는 또 하나의 이유에 대해 말씀드리겠습니다. Google의 Topics에 대한 이야기입니다. Topics는 Google이 21년 Privacy Sandbox의 개념으로 공개한 FLoC을 대체할 기술로 지난 달 (22년 1월) 공개한 개념입니다.
Topics는 쉽게 이야기하자면, 사용자 개인정보가 담긴 쿠키를 개인화에 사용하지 않고 사용자가 방문한 사이트들의 토픽을 추출하여, 토픽만으로 개인화를 수행하겠다는 개념입니다. 토픽은 3주 주기로 사라지며, 디바이스 내 이력만으로 추출됩니다. 크롬에서는 원한다면 옵션을 해제할 수도 있습니다.
라이너 역시 Privacy Preserving 에 항상 관심을 세우고 있기 때문에, 이번 Google의 발제가 굉장히 흥미롭게 다가왔습니다. 라이너가 민감 정보 없이 개인화를 시도하는 과정에서 토픽 모델링을 떠올리고 실험하던 일련의 선택들이 Privacy Preserving 한 방향으로 자리잡게 된 것 같습니다.
(미래라 쓰고, 어려움이라 읽어야 했던) 이번 섹션에서는 라이너가 토픽 모델을 잘하기 위해 해치워야 할 여러 장애물들에 대해 이야기해보았습니다. 토픽 모델을 고도화하기 위해서는 여전히 많은 어려움이 남아있습니다. 하지만, 하나의 기술 발전을 통해 얻을 수 있는 부산물이 너무 많기 때문에 앞으로도 라이너는 토픽 모델에 많은 관심을 쏟을 것 같습니다!
마치며…
제가 라이너에 입사한지도 벌써 반 년이 넘었습니다. 입사 후, 블로그를 통해 세 개의 글을 공유드리게 되었는데 지금 다시 읽어보아도 참 재밌는 문제들을 풀고 있다는 생각이 듭니다. 계속해서 블로그를 통해 라이너가 머신러닝을 통해 어떤 문제를 풀고자 하는지 공유드리는 이유는 딱 하나입니다.
많은 분들이 라이너가 “기술적으로 올바르게 문제를 설정할 줄 알고, 실제로 그 문제를 해결하며 나아가고 있다”라고 공감해주시기를 바라고, 그 공감이 누군가에는 문제를 함께 풀고 싶다는 마음으로 이어지게끔 하기 위해서입니다.
적은 인원이 엄청나게 몸집이 큰 프로덕트를 끌고 나가며 겪는 다양한 문제들에 대한 이야기이기 때문에 부족한 부분도 있을 것이고, 이 글을 읽으시면서도 부족하다고 느끼신 분이 계실거라 생각합니다. 그럼에도 라이너가 해결하고자 하는 문제가 매력적이라는 생각이 드셨다면 그 부족한 부분을 직접 채워주시는걸 고려해주셨으면 좋겠습니다!
더 많은 좋은 분들과 재밌는 문제를 더 많이 풀 수 있게 되기를 바라겠습니다. 다음에는 라이너 셀프 서빙 광고 시스템 구축기라는 주제로 찾아뵐 수 있도록 하겠습니다. 감사합니다 😊
WANTED: 데이터와 기술로 라이너를 더 단단하게 만들어 주실 분
라이너는 전 세계 750만 사용자와 함께 하는 하이라이팅 기반 정보 탐색 서비스입니다. 기존 텍스트 하이라이트에 YouTube 하이라이트까지 등에 업은 라이너에는 매일 텍스트와 동영상 등 다양한 모달리티의 컨텐츠에 대해 수백만 건의 로그 데이터가 쌓이고 있습니다.

라이너는 데이터를 활용해 사용자가 원하는 발전을 위해 소비해야 할 컨텐츠를 큐레이팅 해주는 역할을 대신해주고자 합니다. 라이너가 해결하고자 하는 문제를 풀어줄 모델링을 하고 싶은 머신러닝 사이언티스트, 추론 엔진을 750만 사용자에게 쾌적하게 서빙해보고 싶은 머신러닝 엔지니어 외에도 데이터를 과학적으로 혹은 엔지니어링적으로 잘 다루시는 모든 분들을 기다리고 있습니다!