Sequential Recommenders: 기계들과 회로들
Introduction
안녕하세요, ML 인턴 새미입니다. 작년 12월부터 라이너에서 Sequential Recommender 를 주제로 3개월째 인턴을 진행하고 있습니다. 대학원에서 추천 시스템을 연구해오면서 현실적인 데이터셋과 평가 메트릭의 부재가 언제나 아쉬웠습니다. 많은 회사들이 각자 자체적으로 보유한 데이터에 집중하고 있는 실정이기도 하고요. 이러한 상황에서 연구를 수행함에 있어서 라이너는 저에게 정말로 매력적인 선택지였습니다. 라이너는 “Help People Get Smart Faster” 라는 임무를 가지고 전세계 수백만 유저들의 문서 하이라이팅 이력을 수집하고 있기에, 추천 시스템 학습을 위한 풍부한 데이터를 보유하고 있습니다. 또한, 빠르게 움직이는 스타트업으로서 여러 모델링 아이디어들을 실제 유저 경험 관점에서 빠르게 검증해볼 수 있다는 점도 큰 장점이었습니다. 이번 블로그 글에서는 제가 인턴 기간 동안 시도하고 고민했던 점들을 공유해보려고 합니다 (Note: 이 글에서는 모델링 관련 고민들만 다루었고, 엔지니어링적인 챌린지와 트러블슈팅 과정들은 배제하였습니다).
Domain
지난 3개월 간 정말 다양한 형태의 고민들을 했지만, 돌이켜보면 한 가지 공통된 고민이 전체를 관통하고 있었습니다. 저는 회사 밖에서 공개된 데이터셋만 가지고도 수행할 수 있는 연구를 굳이 라이너 안에서 수행하게 되는 상황을 경계했던 것 같습니다. 다시 말해, 라이너라는 회사와 그 회사가 제공하는 서비스의 본질이 무엇인지 정확히 이해하고, 그 본질이 필연적으로 지시하는 문제들을 풀고 싶었습니다. 반대로 회사의 제품으로부터 격리된 채, 어떤 모델이나 알고리즘이 단지 매력적이어서 적용해보는 일은 최대한 피하고자 했습니다 (그러나 여러 번 유혹에 빠졌습니다). 이것이 회사의 제품에 대해 고민하는 제 나름의 방식이었습니다. 이러한 고민은 현재진행형이기에 이 글은 이 고민에 대한 해답을 명쾌하게 제시하거나 여태까지의 시도들을 평가하는 성격의 글이 되지 못합니다. 제가 이 글에서 다만 해볼 수 있는 것은, 이러한 동기에 의해 움직여 나간 과거의 방향들이 이르렀던 지점들을 다소 난잡하게 갈무리해보는 일입니다.
그렇다면 라이너의 본질은 과연 무엇일까요? 이는 제가 함부로 답하기에는 상당히 위험한 질문입니다. 회사의 핵심을 건드리는 질문이기도 하고, 그 핵심 자체도 중요한 변화를 겪는 와중이라고 보여지기 때문입니다 (예컨대 최근 ChatGPT 의 도래와 발맞추어 이 회사가 이루어 낸 변신을 살펴보십시오). 실제로 최근에 이 본질과 관련하여 몇몇 팀원분들과 긴 시간 토론하는 자리를 갖기도 하였는데, 제가 가장 놀란 부분은 이 회사가 “하이라이팅 유틸리티” 로서의 정체성을 내부적으로 버린지 오래라는 것입니다 (하지만 출근할 때마다 보이는 대왕 형광펜 로고가 저를 가스라이팅 합니다). 오히려 라이너는 플랫폼을 지향하고 있었는데, 그 비전 속에서 사용자들의 스크랩/하이라이팅 이력들은 플랫폼에 새로운 웹 문서들을 유입 시켜주는 부차적인 역할을 수행할 뿐입니다. 오히려 라이너에게 핵심적인 것은 검색과 추천입니다.
이렇게 서비스의 지향점이 바뀌어 감에 따라, 라이너 추천 시스템의 여러 요소들과 관련하여 문제를 재정의 해야 하는 상황이 꾸준히 발생하고 있습니다. 아주 좋은 예시가 whitelist 의 존재입니다. 여태껏 라이너의 추천 시스템은 사용자 경험을 보장하기 위해 “생산적인 콘텐츠”로 간주되는 웹 문서들의 whitelist 를 유지하고 그 안에서만 추천을 하고 있었습니다 (카터의 라이너 블로그 글 참고). 이 whitelist 의 존재 유무만으로도 이미 회사가 지향하는 추천이 “큐레이션”에 가까운지, 보다 넓은 “플랫폼”에 가까운지가 갈리게 됩니다 (여담이지만 현재 ML 플래닛은 이와 관련하여 다소 대담한 도약을 실험 중입니다). 새롭게 정의될 문제들과 데이터 위에서 펼쳐지는 이야기들은 이 글의 2부에서 보여드리는 것으로 하고, 이 글에서는 현재까지의 이야기만 다루도록 하겠습니다.
제가 들어왔을 당시 라이너는 이미 현대적인 추천 시스템을 갖추어 나가는 과정 중에 있었습니다. 자세한 내용은 이 블로그의 다른 글들을 참고하시거나, 얼마전 카터가 모두콘에서 멋지게 발표하신 위의 동영상을 참고하시길 바랍니다. 다만 이 지면에서는 맥락 이해에 도움이 될 만한 몇 가지 사실만 언급하고 넘어가겠습니다.
현재 라이너의 추천 시스템은 일반적으로 사용되는 retriever/ranker 두 단계 구조를 따르고 있습니다. 여러 개의 retriever 모델들이 유저가 관심 있어 할 만한 문서들을 가져오면, ranker 가 한번 더 순위를 매겨서 유저에게 보여주는 구조입니다. 이러한 상황에서 sequential model 을 활용하여 retriever 단계를 고도화 하는 것이 저의 프로젝트였습니다.
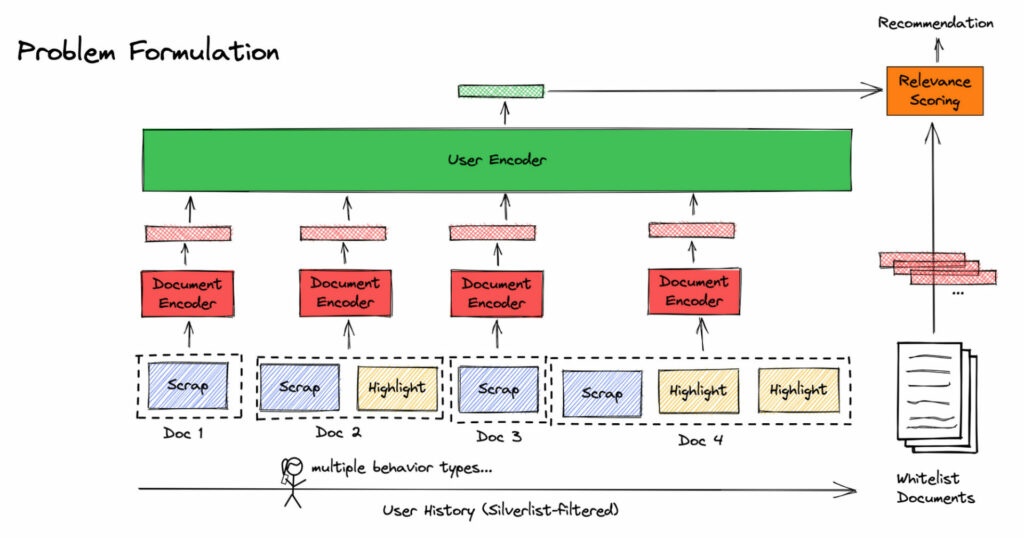
Sequential Recommender 문제를 거칠게 표현하면 “유저가 본 아이템들의 sequence 가 주어졌을 때, 다음 아이템을 추천하기” 라고 할 수 있습니다. 라이너의 경우 유저가 소비한 웹 문서가 아이템에 해당됩니다. 이때 모델은 크게 두 단계로 나뉘게 되는데, 각 문서를 임베딩 벡터로 치환하는 Document Encoder 와, 유저가 본 과거 문서들의 임베딩 벡터들이 주어졌을 때 유저 벡터를 뽑아내는 User Encoder 가 그것입니다. 그렇게 도출된 유저 벡터를 가지고, 문서 풀에서 ANN 을 활용하여 관련성이 높은 문서를 끌어오게 됩니다.
이미 이 단계에서 라이너만이 가지는 도메인의 특성들이 드러나기 시작합니다. 우선 라이너에서 다루는 아이템이 웹 문서라는 사실이 주목할 만 합니다. 웹 문서는 다분히 언어적이라는 특성을 갖고, 또 새로운 문서들이 지속적으로 추가된다는 특성을 갖습니다. 이런 상황에서는 콜드 스타트 문제를 피하기 위해 NLP 모델을 사용하여 아이템을 임베딩하는 방식이 바람직할 것입니다. 실제로 라이너는 이미 MiniLM 등의 pre-trained multilingual model 을 fine-tuning 한 모델을 가지고 웹 문서를 임베딩하고 있었습니다 (카터의 라이너 블로그 글 참고).
여담이지만, 저는 처음에 최대한 자유롭게 사고해보려고 했습니다. “이미 주어진” 임베딩 벡터들을 가지고 User Encoder 의 구조만을 고민하는 작업은 쉽게 단조로워질 위험이 있다는 사실을 이전에 경험했기 때문입니다 (”attention 모듈 가지고 레고 블록 쌓기!”). 말하자면, 라이너만이 가진 데이터의 특성을 최대한 활용해보고 싶었습니다. 이를테면 라이너는 유저가 웹 문서의 어떤 부분에 하이라이팅을 했는지에 대한 정보를 가지고 있습니다. 이를 활용하도록 Document Encoder 를 디자인하면, 더욱 질이 좋은 임베딩 벡터를 얻을 수 있지 않을까요? 하지만 이러한 생각은 금새 현실적인 어려움에 부딪혔는데, 유저들은 심리적 허들로 인해 생각보다 하이라이팅을 많이 하지 않는다는 사실을 팀원분들이 알려주었기 때문입니다. 실제 이러한 이유로 인해 하이라이팅 뿐만 아니라 유저가 단순히 스크랩한 문서까지 활용하여 추천을 하고 있는 상황이었습니다. 게다가 이미 성능이 입증된 카터의 NLP 모델을 활용하여 추천 모델에 입력될 아이템 임베딩들과 마지막에 유저 벡터로 ANN 을 수행할 문서 풀의 임베딩들이 구해져 있다는 사실을 고려하면 새로운 문서 임베딩 방법을 고민할 동기가 그렇게 크지 않았습니다.
라이너만이 가지는 도메인의 특성은 이에 그치지 않습니다. 더욱 흥미로운 것은 아이템의 sequence 가 가지는 특성입니다. 현재 라이너에서 관측되는 아이템의 sequence 들은 사용자들이 웹 브라우징을 하면서 “자발적으로” 따라간 경로들입니다 (이를 document journey 라고 부르겠습니다). 이는 여러 측면에서 흥미롭습니다. 우선 피드백 루프에서 자유롭다는 측면이 있습니다. 추천 시스템에서 피드백 루프는 유명한 문제입니다. 보통 사용자들은 시스템이 보여주는 아이템들과 상호작용하기에, 시스템이 발생시킨 데이터가 미래의 시스템 학습에 되먹임 되는 문제가 발생합니다. 그러나 사용자들의 자발적인 document journey 에서 유의미한 신호들을 학습해낼 때는, 비록 다른 confounder 들은 여전히 잔존하겠지만, 적어도 우리의 시스템의 영향을 신경 쓰지 않아도 된다는 점이 흥미로웠습니다. 두번째로 document journey 라는 사실 자체가 흥미로웠습니다. 사실 이와 관련하여 저는 약간의 착각을 한 적이 있는데, 라이너는 사람들의 웹 여정을 조금 더 똑똑하게 만들어주는 navigator 역할을 지향하는 줄로 알았던 것입니다. 실제로 이 착각에서 비롯한 어느 한 연구 갈래가 밑에서 서술될 예정입니다. 세번째로, 웹 상에서의 document journey 는 당연히 noisy 할 수밖에 없다는 특성이 있습니다. 이를 타개하기 위해 앞서 언급한 whitelist (그리고 blacklist) 가 이미 작동하고 있지만, 추가로 모델 단에서 denoising 을 자동으로 수행할 수 있게끔 하는 것도 흥미로운 연구주제가 될 것입니다.
그러나 라이너는 사실 플랫폼을 지향하고 있기 때문에, 미래에는 이러한 도메인 특성이 많이 바뀔 수가 있습니다. 왜냐하면 사용자들의 document journey 가 아니라 사용자들이 우리의 플랫폼 안에서 발생시킨 로그들의 sequence 를 다루게 될 것이기 때문입니다. 이는 단점이자 장점으로 작용할 수 있습니다. 우선 피드백 루프가 재도입되고, document journey 가 가지는 특성이 퇴색된다는 것은 단점입니다. 그러나 플랫폼이 잘 갖추어짐으로 인하여, noise 는 줄고 유용한 피쳐는 (가령 dwell time) 늘어나게 된다는 점은 장점입니다. 또한 문제가 정형화될수록, 기존 연구들을 더 많이 레퍼런스 할 수 있다는 점도 큰 장점입니다.
이로써 제가 풀어야 했던 문제가 놓여 있던 도메인의 특성을 간략하게 살펴보았습니다. 바뀌어 가는 도메인의 특성을 고려하여 좋은 문제를 정립하는 일은 미래의 작업으로 남겨두고, 남은 지면에서는 이때까지 했던 작업들을 시간 순으로 되돌아보도록 하겠습니다.
그놈의 Transformer
딥러닝 시대가 여기까지 진전해 온 상황에서, Transformer 모델에 대하여 제가 구태여 구구절절 설명할 필요는 없을 듯 합니다. Transformer 는 문장을 구성하는 단어들처럼 순차성을 갖는 데이터를 입력으로 받아서, 그 데이터에 내재한 패턴들을 파악해내는 모델입니다. 2017년 구글에서 3개월만에 조립된 이 기계는 후에 AI 분야 전반을 떠받치는 파운데이션 모델로 자리하게 됩니다 (여담이지만, 이 3개월을 잘 들여다보면, 속도 라는 성질이 기계의 조립에 관여하는 흥미로운 지점들을 발견할 수 있습니다). 이때 파운데이션 모델이라 함은 (애초에 Transformer 가 목표하던) 텍스트 처리 분야를 넘어서, 이미지 처리, 음성 처리, 단백질 처리 등의 다양한 분야들까지 단일한 모델이 아우르게 되었음을 의미합니다. 당연히 추천 분야도 예외가 아니었습니다.
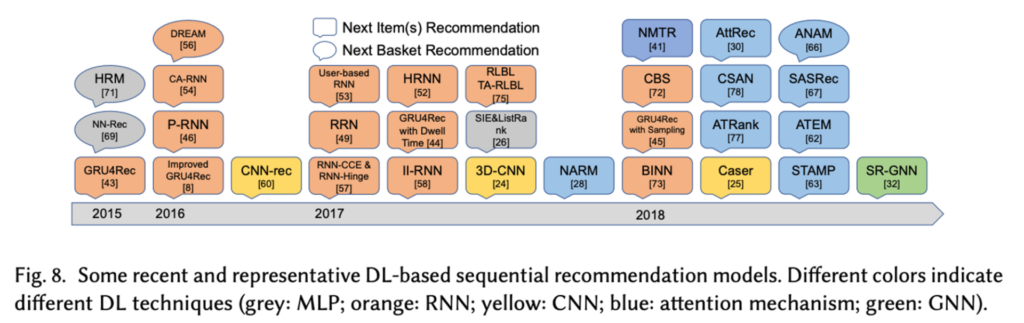
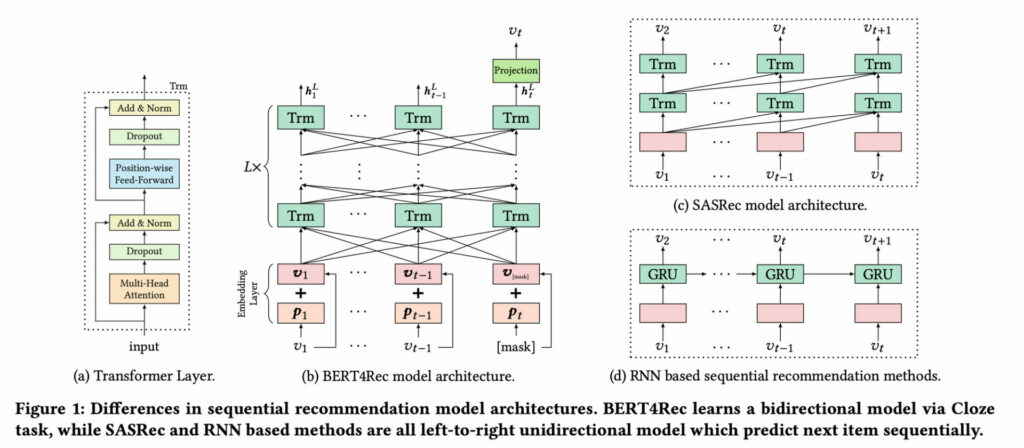
제가 대학원에 입학할 무렵인 2019년 즈음에 BERT4Rec 논문이 공개되었습니다. 언어 처리 분야에서 이미 엄청난 성공을 거둔 Transformer 모델을 그대로 Sequential Recommendation 문제에 적용하여 좋은 성능을 거두었다는 내용입니다. 단어들의 sequence 대신 아이템들의 sequence 들을 고려한다는 간단한 발상이었습니다. 생각해보면 이러한 논문이 나오는 것은 어쩌면 당연한 수순이었을지도 모릅니다. 위의 2019년 서베이 논문을 참고해보면 과거에 MLP, RNN, CNN 등의 딥러닝 모듈들이 나올 때마다 그것들을 그대로 Sequential Recommendation 문제에 적용해보는 기조가 이어져오고 있었고, 마지막에 등장한 SASRec 을 비롯한 attention 계열 모델들은 Transformer 기반의 접근법을 분명히 가리키고 있었기 때문입니다. 저 또한 개인적으로 BERT4Rec 을 베이스라인 삼아, timestamp 정보를 활용하여 모델 정확도를 높이는 아이디어로 작지만 소중한 논문 을 2020년 RecSys 학회에 출판한 바 있습니다.
라이너 또한 사용자들의 document journey 라는 순차적인 데이터를 풍부하게 가지고 있습니다. 여기에 Transformer 모델을 적용하여 패턴을 학습한다는 생각을 자연스럽게 해볼 수 있을 겁니다. 우선 모델의 입력으로 사용될 임베딩 벡터들의 sequence 가 필요합니다. 우리의 경우 사용자가 최근에 스크랩 한 문서들을 (가령 50개) 히스토리로 사용하였고, 앞서 언급한 Document Encoder 를 활용하여 각 문서를 임베딩 벡터로 치환하였습니다. 다음으로 Transformer 모델을 구현해야 했는데, 과거엔 self-attention 모듈부터 하나하나 직접 구현하여 쌓아 올렸던 반면에, 이번엔 reproducibility 에 대한 걱정을 덜기 위해 아예 huggingface 에서 Transformer 를 끌어와서 사용하였습니다. 그 후, Transformer 를 학습시키는 일반적인 방식을 따라, 유저가 다음에 클릭할 확률이 높은 문서를 맞추도록 학습시켰습니다. 다음 문서를 맞출 때는 모델의 최종 단에서 출력된 벡터와의 유사도를 활용하게 되는데, 수행 시에는 그 벡터를 유저 벡터로 간주하게 됩니다.
결과적으로 이렇게 학습된 sequential recommender 모델이 베이스라인 모델에 비해서 성능 개선이 있다는 점을 보였습니다. 베이스라인 모델은 유저가 최근에 본 문서 임베딩들을 단순히 평균 내어서 유저 벡터를 구하는 방식으로써, 현재 서빙 되고 있는 NLP retriever 모델을 다소 거칠게 흉내 낸 것입니다 (이 라이너 블로그 글을 참고하시면, 실제 NLP retriever 모델은 이보다 훨씬 더 세련되게 동작하고 있음을 알 수 있습니다). 모델의 성능을 평가함에 있어서, 처음에는 (일반적인 추천 논문에서 그렇게 하듯이) 정답 아이템과 함께 100개 가량의 랜덤한 negative 아이템을 뽑아서 모델이 정답 아이템의 점수를 나머지 negative 아이템과 비교하여 얼마나 높게 매기는지를 기준으로 삼았습니다 (위의 사진). 그러나 실제 서빙 환경에서는, 우리의 모델이 출력한 유저 벡터를 활용하여 전체 문서 풀에 대해서 ANN 을 수행하게 됩니다. 이러한 평가 메트릭의 괴리 때문에 오프라인 실험 환경에서 모델의 실제 배포 성능을 가늠해볼 수 없다는 한계점이 있었습니다. 따라서 나중에는 faiss 를 활용하여 오프라인 실험 환경에서도 모델의 실제 retrieval 성능을 평가할 수 있도록 하였습니다.
오프라인에서 어느 정도 성능 검증을 마친 후에 seqrec 을 실제 서비스에 배포하였습니다. 배포된 seqrec 은 준수한 CTR 을 보여주면서 무리 없이 동작했습니다. 그 후 negative sample 개수를 대폭 증가시키거나, encoder 모델을 decoder 모델로 교체하는 등의 개선들을 거치며 현재 ver 1.2 가 돌아가고 있는 상황입니다. 서로 다른 retriever 모델들의 CTR 에 대한 엄밀한 비교분석이나 추적은 잘 이루어지지 못했는데, 왜냐하면 마침 웹과 앱의 디자인과 그 안에서의 로그 수집 형태가 크게 바뀌고 있었기 때문입니다 (자세한 사항은 저보다 더 자격 있는 분이 글을 적어 주시리라 믿습니다). 조만간 플랫폼이 안정화되고 나면 보다 더 엄밀한 분석들이 이루어질 수 있을 거라고 보입니다.
Seqrec 배포를 성공적으로 마치고 나서 저는 “새로울 것이 무엇인가?” 라는 고민에 빠져들었습니다. 새로움에 대한 고민은 여러 원천에서 비롯하였습니다. 우선 지극히 현실적인 이유로써, 논문에 대한 고민이 있었습니다. 대학원생으로서 탁월함을 보여줄 증거이자 실적으로 남는 것은 주로 논문이기에 논문을 쓰겠다는 목표를 가지고 라이너 인턴을 시작하였는데, 그러자면 어떤 형태로든 novelty 가 필요했기 때문입니다. 그리고 조금 더 개인적인 이유로 성장에 대한 갈망이 있었습니다. 제가 라이너 팀원들을 보면서 놀랐던 것 중 하나는 성장에 대한 강박에 가까운 집착이었습니다. 지속적으로 회고하며 스스로가 질적으로 달라졌는지 검토하는 그들의 모습은 저로 하여금 같은 질문을 던지게 하기에 충분하였습니다. Transformer 자체보다는, Transformer 를 가지고 몇 해 전과 비교하여 질적으로 다른 일을 해내고 있지 못한 스스로의 모습에 염증을 느껴서 자꾸만 새로운 연구 방향들을 탐구했던 것 같습니다.
그 중 한 방향은 Causality 였습니다.
Causality
최근 추천 연구 문헌들에는 causality 개념이 많이 등장하고 있습니다. Judea Pearl 교수가 제안한 do-calculus 와 Structural Causal Model 은 비단 associational 한 관계 P(Y|X) 를 넘어서 interventional 한 관계 P(Y|do(X)) 와 counterfactual 한 관계 P(y_{x’}|x,y) 까지 다룰 수 있는 개념적 프레임워크를 제공합니다. Causality 와 ML 의 전반적인 접점과 관련하여 이 논문을 참고하면 좋을 것 같습니다. 추천 연구에 국한해서는 이 논문이 잘 정리해둔 것 같습니다.
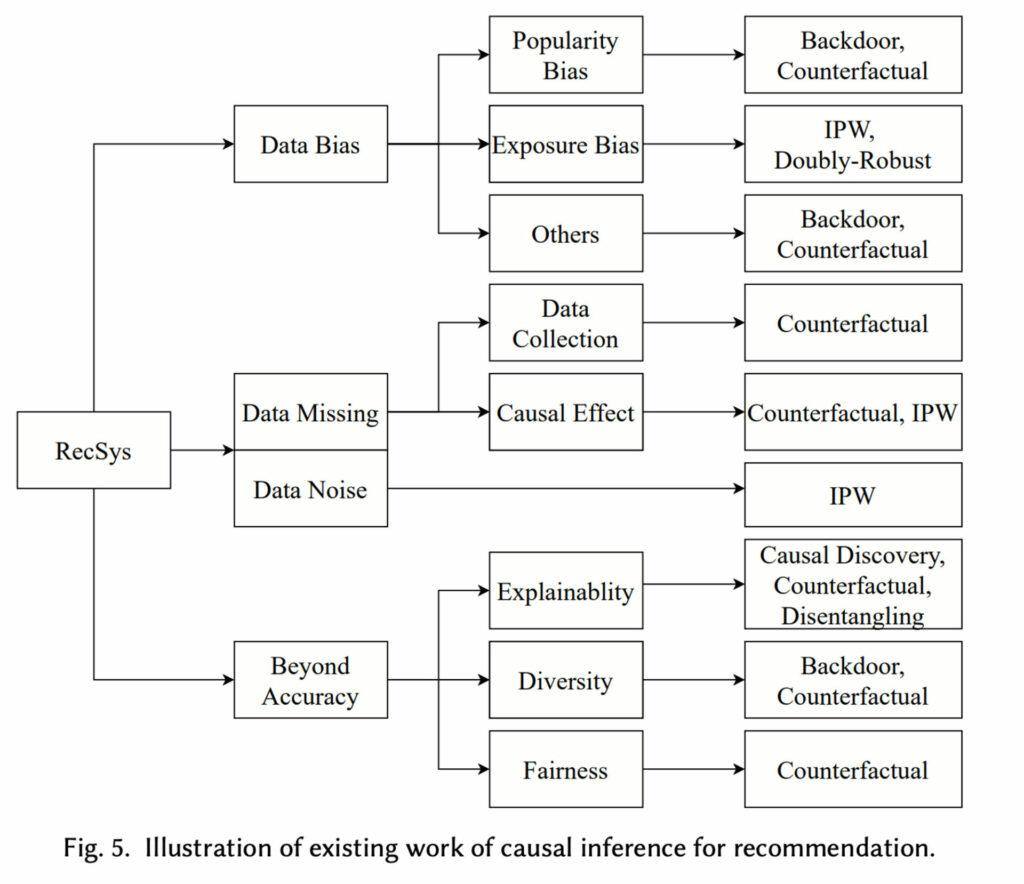
서베이에서 보였듯이, 추천 분야에서 causal inference 는 주로 학습 데이터에 내재한 각종 bias 를 해결하는 데에 쓰이고 있습니다. 예를 들어 이 논문 에서처럼
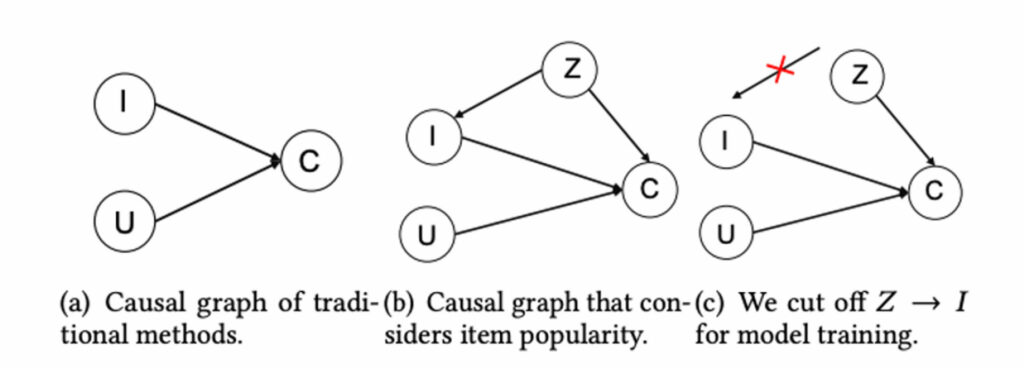
아이템, 유저, 클릭 등의 변수들 사이의 인과관계를 나타내는 causal graph 를 제안하고, 그 graph 안에서의 confounder 를 제거하기 위해 do-calculus 를 사용합니다.

그 결과 그들 간의 상관관계가 아니라 인과관계를 학습 및 추론할 수 있다는 것이 이러한 논문들의 골자입니다. 이 계열의 다른 논문들 또한 각자 조금씩 다른 causal graph 를 제시하면서 출발하긴 하지만 결국엔 본질적으로 동일한 스토리를 따라간다고 저는 이해하였습니다.
이러한 접근법은 causal graph 를 알고 있다는 전제에서 출발합니다. 물론 그것이 현실을 근사하기 위해 저자들이 제안하는 가정일 뿐이라 할지라도 말입니다. 반면에 causal graph 를 알지 못할 때 그 구조를 발견하는 방법론을 causal structure discovery 라고 합니다. 이 당시 저는 라이너 데이터 위에선 causal structure discovery 를 적용하는 것이 더 어울린다고 생각했던 것 같습니다. 아마 이 또한 라이너의 서비스 특성을 최대한 살려보려는 고민에서 비롯했던 것 같습니다. 앞서 언급했듯이 저는 라이너의 임무인 “Help People Get Smart Faster” 가 “웹 상의 네비게이터” 같은 형태로 구현되리라는 작은 착각을 하고 있었던 것입니다. 사람들이 웹에서 학습을 할 땐 임의의 순서로 이동하지 않으며, 하나의 지식이 다른 하나의 지식을 가리키는 필연적 연쇄를 따라서 그렇게 합니다. 사용자들의 하이라이팅 히스토리라는 잡음이 가득한 데이터 뭉치에서, 여럿이 공통된 순서를 따라 “Get Smart” 해진 일련의 인과적 사슬들을 발견해낼 수 있다면 그러한 기술이야말로 이 회사가 제공하고 싶은 서비스의 중핵에 가까운 것이 아닌가, 하는 생각을 했던 것 같습니다.
하여, GOLEM 이라는 기법을 라이너 데이터에 실험적으로 적용해보기에 이릅니다. 그 결과 일견 흥미로우면서도 한편으로는 당연한 causal DAG 들을 여럿 발견하였습니다. DAG 들을 가지고 놀면서 재미를 보기도 했고, ML 위클리 때 팀원들에게 causality 관련 연구들을 공유하는 시간을 갖기도 하였습니다. 그러나 이 모든 작업은 Proof of Concept 에 불과한 것이어서 실제로 적용 가능한 수준이 되기 위해서는 몇 가지 문제점들을 해결해야 했습니다.
일반적인 causal reasoning 은 N개의 discrete 한 확률변수를 필요로 합니다. 위에서처럼 GOLEM 을 라이너 데이터에 실험적으로 적용해보기 위해서 저는 우선 각각의 웹문서를 변수로 두고, 유저마다 상호작용한 모든 문서들의 값을 1, 그렇지 않은 문서들의 값을 0으로 둬서 각각의 유저를 하나의 데이터 포인트로 취급했습니다. 그러나 새로운 웹문서가 지속적으로 추가되는 상황에서 이와 같은 방식은 스케일러블 하지 않습니다 (그렇지 않은 상황에서도, 문서들의 개수가 수백만개에 달한다는 사실을 고려하면 바람직한 방식이 아닙니다).
이를 해결하기 위해 Sequential Recommendation with User Causal Behavior Discovery 같은 논문은 클러스터링을 사용합니다. 아이템들의 클러스터 수준에서 Causal DAG 를 구한 다음, 이 정보를 Sequential Recommendation 모델에 통합한다는 아이디어입니다.
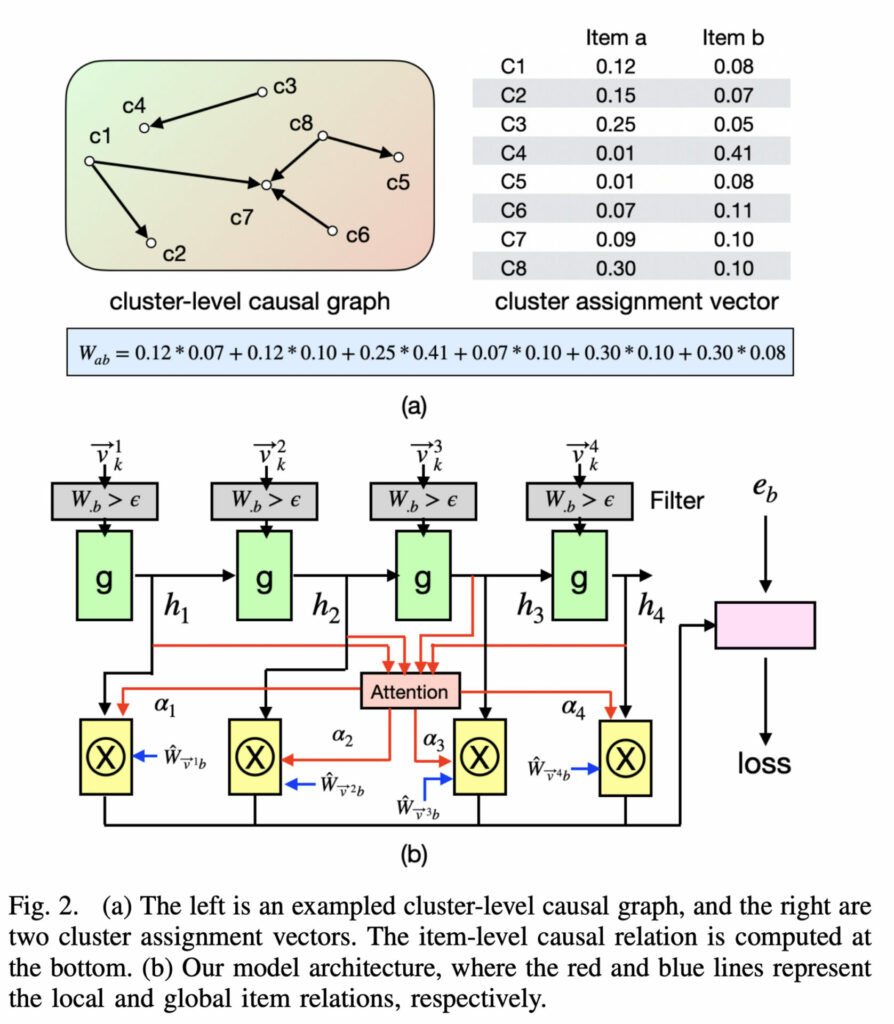
이를 벤치마킹하기 위해서 우리도 문서들의 클러스터를 구할 필요가 있었습니다. 라이너는 아직 문서별로 카테고리나 태그 분류가 되어 있지 않은 상황이기에 (하지만 카터가 열심히 작업중이십니다. 커밍순!), 대신 문서 임베딩을 가지고 K-means 등의 방법으로 클러스터를 구하는 것이 자연스러워 보였습니다. 하지만 이 경우, 적절한 클러스터의 크기 (혹은 클러스터의 개수) 가 무엇이냐 하는 문제와 맞닥뜨리게 됩니다. 극단적으로 말해서, 가장 거칠게 묶을 경우 모든 아이템이 하나의 클러스터로 묶여서 인과 구조가 무의미하게 되고, 가장 잘게 나눌 경우 각 아이템이 자기만의 클러스터로 묶이게 되는데 이는 정확히 우리가 앞서 피하고자 했던 상황입니다. 따라서 그 중간 어딘가에 sweet spot 을 찾아내야 하는데, 클러스터 개수 250개 정도로 실험해보기도 하고, 아예 topic modeling 을 사용하여 문서들의 토픽을 클러스터로 간주해보기도 하고, 여러 아이디어들을 실험해 보았던 것 같습니다.
그러나 그런 식으로 얻어낸 클러스터 수준의 Causal DAG 가 성능에 개선을 가져다 주는지는 의문이었습니다. 아주 간단한 예시로, 현재 문서 임베딩만 가지고 다음 문서를 예측하는 베이스라인 모델에, Causal DAG 관련 logit 들을 통합해보아도, 성능에 뚜렷한 개선을 얻을 수 없었습니다. 생각해보면, 느슨하게 구해진 클러스터들 사이의 인과적 관계는 큰 도움이 안 될지도 모릅니다. 예컨대 “IT” 클러스터에서 “소프트웨어” 클러스터로 넘어갈 확률이 높다는 사실이 next item prediction 에 과연 얼마나 도움이 될까요? 게다가 처음 꿈꾸었던 대로 정말 유저가 똑똑해지는 데에 도움이 되는 사슬을 제공하려면 가령 “딥러닝”-”역전파”-”MLP”-… 이런 식으로 이어지는 클러스터들을 구성해내야 할 텐데, 이를 자연스럽게 얻어내는 일 또한 쉽지 않아 보였습니다.
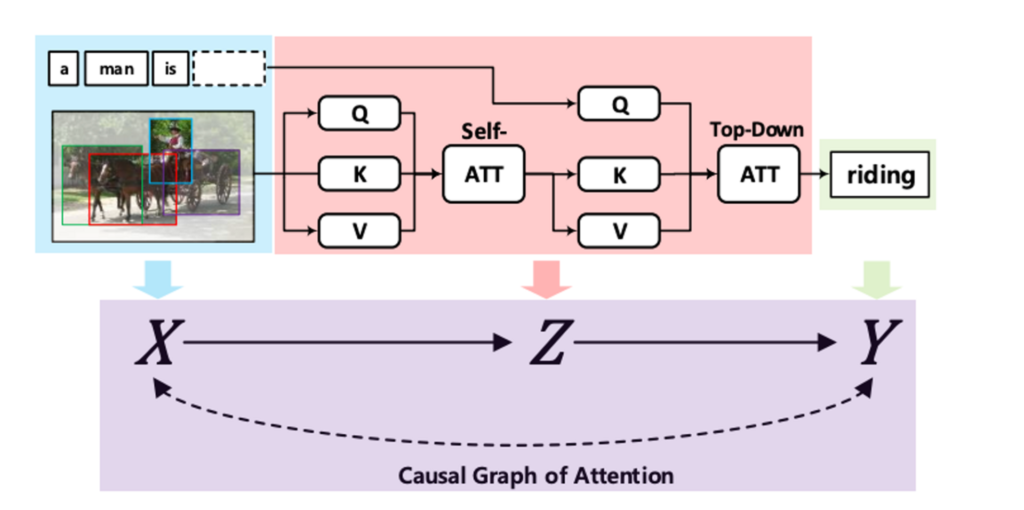
결국 이 모든 건 high-level semantic concept 을 결여하고 있기 때문에 발생하는 일이었습니다. 그런데 딥러닝 모델이 내부적으로 배우는 것이 정확히 그러한 고수준 개념들이 아니던가요? 고수준 개념을 클러스터링 등의 인위적인 방법으로 주입해주는 것이 아니라, 모델 안에서 자연스럽게 학습되고 있는 고수준 개념들에 대하여, 추가적으로 그들 간의 인과적 관계까지 배우도록 구조적으로 강제할 수 있다면 꽤 우아할 것이라고 생각했습니다. 이를테면 어텐션 모듈을 개조해서 자연스럽게 front-door adjustment 가 수행되도록 한 이 논문처럼 말입니다.
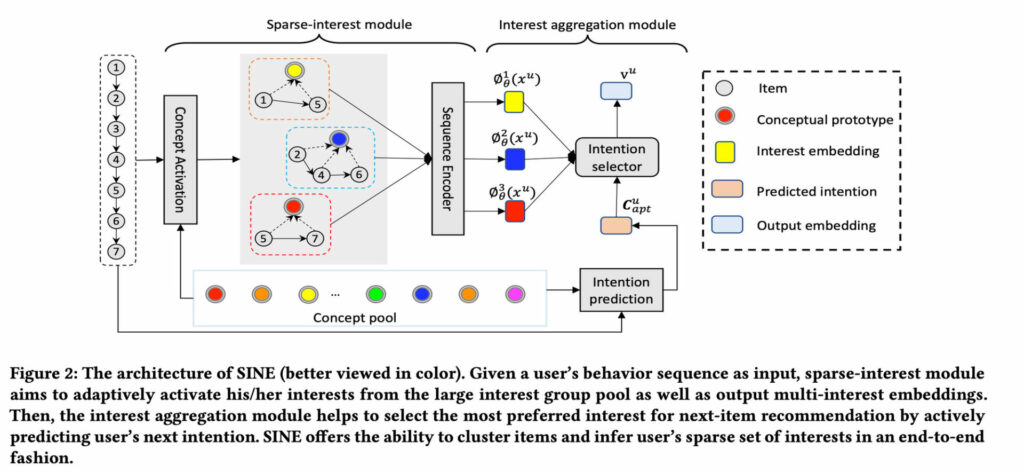
혹은 “causal reasoning 을 수행하기 위해 모델 내부에 어떻게든 여러 개의 고수준 개념들이 나오면 좋겠다” 는 생각에, multi-interest 관련 문헌들을 괜히 다시 들추어보기도 했습니다. 가령 모델 내부적으로 concept pool 을 유지하는 아래 논문이나,
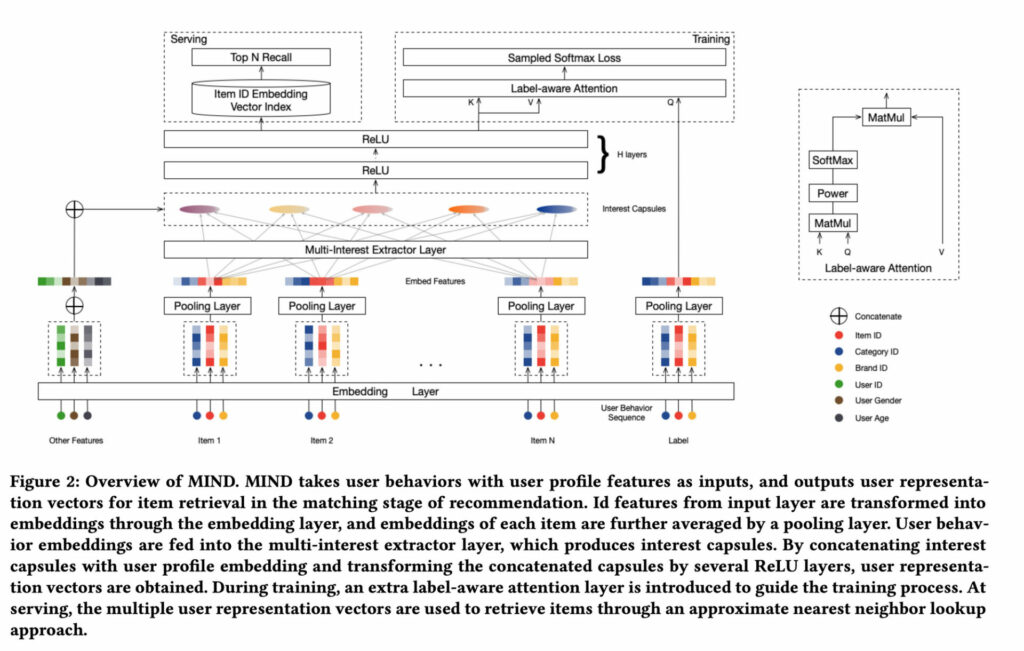
routing 메커니즘으로 multi-interest 들을 묶어내는 아래 논문들처럼 말입니다.
게다가 NO TEARS 로부터 시작된 causal structure discovery 방법들의 계열은 (GOLEM 포함) 생각보다 간단해서, 이를 딥러닝적으로(?) 녹여내야 한다는 저의 생각을 더욱 강화 시켜 주었습니다. 알지 못하는 causal graph 로 부터 생성된 데이터 포인트들 X 가 있을 때, 이들이 얻고자 하는 바는 X 를 설명하는 causal graph A (such that X ~= XA) 인데, 이때 A 에 cycle 이 없도록 강제하는 DAG constraint 를 continuous optimization 방식으로 풀 수 있도록 아이디어를 낸 것이 핵심이었습니다 (이전엔 모든 가능한 그래프 형태를 문제 공간으로 삼는 combinatorial 한 문제였습니다).

그러나 (sequential) recommender 의 역사를 되돌아 보면, 애초에 X ~= XA 수준의 예측보다 더욱 좋은 예측을 하는 모델을 만들기 위해 고군분투해 온 역사가 보입니다. 그렇게 해서 도달한 현재의 딥러닝 모델들로 예측 모델을 대체하고, DAG constraint 만 남겨 놓는다면 어떻게 될까요? 헌데, 딥러닝 추천 모델은 주로 두 개의 임베딩 벡터를 내적 하여 점수를 내는데 이런 식의 연산은 본질적으로 acyclicity 와 거리가 멉니다. 그렇다면 방향성을 갖는 새로운 distance metric 을 고민해봐야 하는 걸까요? 이쯤 되니 DAG constraint 가 과연 무슨 소용인가 하는 생각마저 듭니다. 단순히 cycle 이 없도록 강제하는 것과, 문서들 간의 실제 인과관계 사이에는 과연 얼마만큼의 본질적 연결고리가 존재할까요…?
이 즈음에도 팀원들과 본질에 대한 대화를 많이 나눈 것 같기도 합니다. 이를테면 라이너에서 sequential recommender 가 제공해야 하는 서비스의 본질이 무엇인지에 대하여. 학계에서 “sequential recommender” 라는 용어를 쓰는 방식에 익숙해져 있던 저는 당연히 “유저의 과거 아이템 sequence 로부터 다음 아이템을 개인화 하여 추천하는 문제”로 이 용어를 사용하고 있었는데, 프로덕트에 대한 고민을 주로 하는 어떤 분은 “sequential” 이라는 단어에 주목하여 “가령 pinterest 에서처럼, 개인화와는 무관하게 서로 연관 있는 아이템들을 sequential 하게 추천하는 문제” 로 이 용어를 사용하고 있었다는 사실이 뒤늦게 밝혀지기도 했습니다. 우리는 sequential recommendation 과 session-based recommendation 의 문제 정의를 두고 혼란스러워 하기도 했고, 틱톡이나 인스타그램 릴스의 알고리즘의 본질을 두고 궁리하기도 했습니다 (공교롭게도 라이너 앱의 인터페이스는 이 무렵부터 숏폼 형식으로 바뀌어 갑니다…).
현재 Causality 와 관련된 고민들의 계열은 벌어진 상처처럼 열려 있는 상황입니다. Seqrec 첫 배포 도중 맞닥뜨린 (여기선 자세히 서술하지 않을) 문제들을 해결하기 위해 잠깐의 맥락 전환이 있었고, 그 문제들이 해소되고 난 후에도 저는 인과에 대한 고민을 이어가는 대신 회로들에 대한 작업으로 들어가기 시작했기 때문입니다.
Circuits
제가 인턴을 시작한 12월 즈음부터 ChatGPT 가 뜨거운 화제가 되기 시작했습니다. 바야흐로 LLM (Large Language Model) 춘추전국시대가 열렸고, Transformer 라는 기계가 석유처럼 모든 것을 구동하고 있습니다 (물론 다소 거친 일반화입니다). 이러한 와중에 이런 거대 규모 AI 모델의 안전성이나 윤리성과 관련하여 사업을 벌이고 있는 주체들이 있습니다. 이를테면 Anthropic 이 그러합니다. Anthropic 팀의 목표는 명확한데, “Reliable, interpretable, and steerable AI systems” 를 만들기 위해 그들은 LLM, 특히 Transformer 모델에 대한 mechanistic interpretability 에 도달해야 합니다. Distill 의 Circuits Thread 에 영감을 받은 그들은, Transformer 에 대해서 비슷한 작업을 진행중입니다 (Transformer Circuits). Circuit 이란 인간이 이해할 수 있는 동작을 보이는 신경망의 부분회로들을 지칭합니다. 비전 모델에서의 curve detector 가 그런 회로의 한 예입니다.
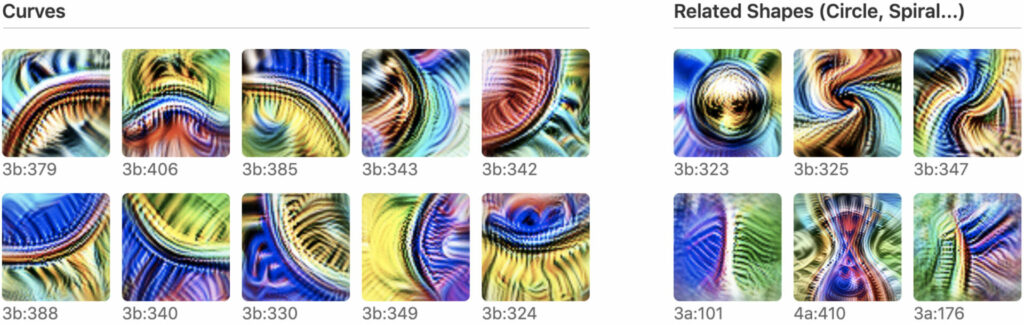
Anthropic 의 저자들은 이와 같은 circuit 들을 Transformer 모델 안에서 찾아내기 위해 노력합니다. Thread 의 첫번째 글 에서 그들은 전체 Transformer 모델에 바로 덤벼드는 대신 아주 간단한 Toy Model 을 고안합니다. 즉 Transformer 의 self-attention 부분만 남기고, 분석에 방해가 되는 나머지 부분들 (Feed-Forward, LayerNorm, bias) 등을 제거합니다. 그 후 이 Toy Model 안에서 attention head 들이 구성하는 회로들에 대한 일련의 개념화를 시도하는데, 여기에는 다소 우아한 관점의 전환들이 요구됩니다.
예를 들어 zero layer Transformer 는 bigram statistics 를 모델링하는 것으로 보여져야 합니다. 맥락에 대한 고려 없이 오직 현재 단어에서 다음 단어를 예측하기 때문에 그렇다는 것이죠. 그 다음, 그 위에 self-attention 를 한 겹 얹은 one layer Transformer 에서 그들은 QK circuit 과 OV circuit 을 발견합니다.
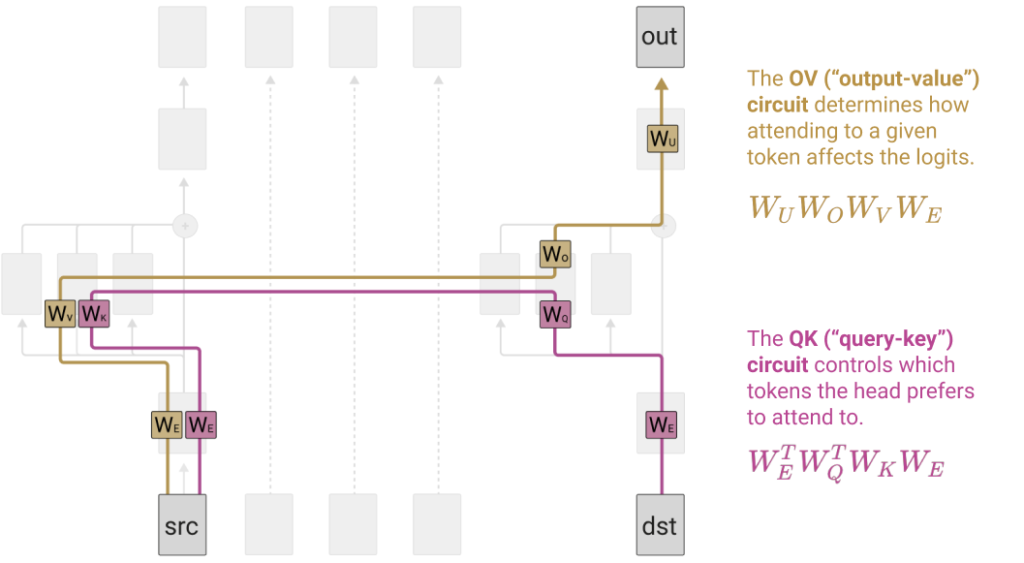
이때 QK circuit 의 역할은 특정 query 가 어떤 key 들에 더 주목하는지 (혹은 거꾸로 특정 key 가 주로 어떤 query 들에 의해 주목되는지) 를 지정하는 것이고 OV circuit 의 역할은, 특정 key 가 주목되었을 때, 자신이 최종 logit 에 어느 정도로 영향을 끼칠지 지정하는 것입니다. 이 경우에 이 회로들의 내부에 대한 궁금증이 자연스럽게 뒤따르게 됩니다. 예를 들어서 특정 단어는 다른 어떤 단어에 의해 강하게 attend 될까…? 회로들이 너무 거대하기 때문에 전수조사를 수행하는 것은 불가능하고, 대신 Anthropic 은 QK, OV 중 값이 큰 쌍들을 골라서 “흥미로운” entry 들을 뽑아보는 시도를 합니다.
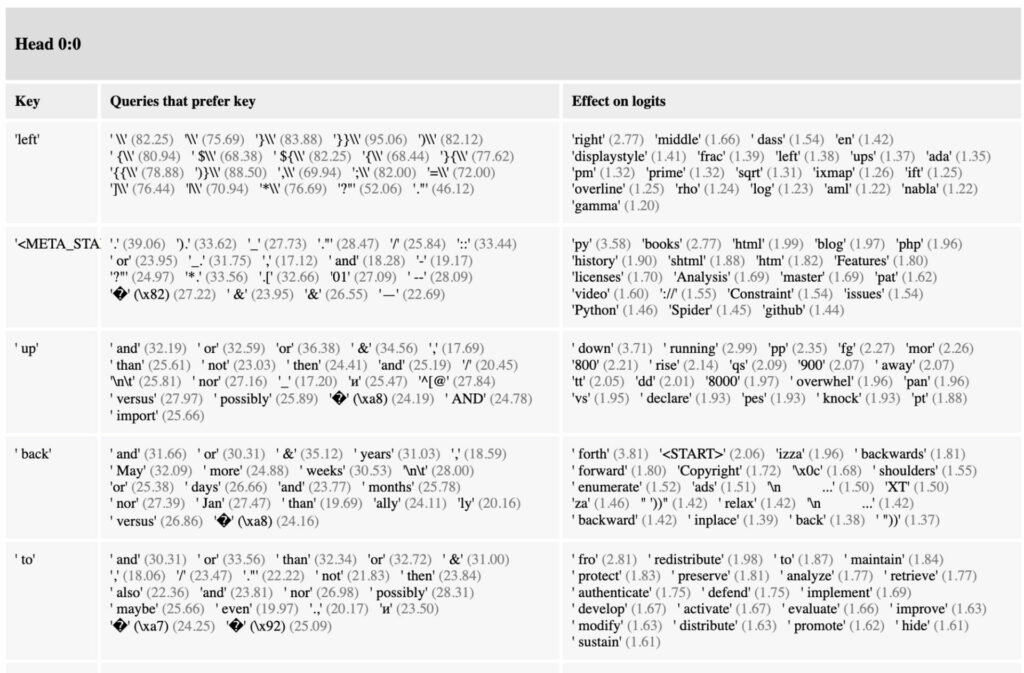
그리고 그들은 대부분의 attention head 가 “copying” 연산에 사용되고 있다는 사실을 발견합니다.

즉 b…a→b 형태의 skip-trigram 을 배우고 있고 (zero-layer 는 a→b 형태의 bigram 을 배우고 있었다는 사실을 상기하기 바랍니다), 이로인해 아주 원초적인 형태의 in-context learning 이 시작되고 있다는 것입니다.
그 후 two layer Transformer 모델부터는 depth 가 생기면서 attention head 간의 “합성”이 가능해지게 됩니다. 즉 query, key, value layer 들이, 단순히 단어 임베딩이 아니라 “이전 layer 의 attention head 의 결과들” 에도 적용될 수 있다는 이야깁니다. 이를 각각 Q-composition, K-composition, V-composition 이라고 부릅니다. 저자들이 조사해본 결과 이 중 K-composition 의 효과가 가장 두드러지는데, 이 효과로 인해 induction head 라는 것이 탄생하게 됩니다. induction head 는 ab…a→b 형태의 매칭을 수행합니다 (즉 prefix matching). 이게 가능한 것은 아래와 같이 “한 칸 전 token”들로 shift 되게 key 를 합성할 수 있기 때문입니다.

이는 더욱 고도화된 in-context learning 이며, depth 가 쌓일수록 더욱 복잡한 형태의 합성이 가능해진다… 라는 것이 저자들의 요지입니다. 이를테면 ab…a→b 뿐만 아니라 a’b’…a→b 처럼 a, b 와 유사한 a’, b’ 를 매칭하는 작업도 가능해지고, 여기서 이를테면 번역 기능 등이 창발한다고요. 이러한 초기의 통찰들을 Transformer Circuits 의 나머지 글들에서 어떻게 발전시켜 나가는지도 살펴보는 것도 매우 흥미로우나, 그걸 다 요약하는 건 제 몫이 아니니 원글을 참고하시길 바랍니다.
Seqrec 첫 배포가 성공적으로 마무리되고 난 후에, 저는 Transformer 가 언어모델이 아니라 Sequential Recommender 로써 활용될 때 그 안에서 어떤 circuit 들이 생겨나는지 분석해보는 작업에 매달렸던 것 같습니다. 정확히 어떤 사고 경로를 따라 이러한 작업에 집착하게 되었는지는 기억하지 못합니다. Thinking Like Transformers, Tracr 등의 논문들을 통해 Anthropic 의 Transformer Circuits 로 이어졌던 것은 기억합니다. 아마 이 당시 저는 Interpretability 나 Explainability 등의 테마에 사로잡혀 있었던 것 같은데, 그 호기심 중 일부는 causal structure discovery 에 대한 작업으로부터 이어져 내려오던 것이었고, 나머지 일부는 Transformer 를 blackbox 취급하면서 돌려오던 막연한 작업 방식에 대한 권태에서 비롯하였던 것 같습니다. 이 무렵 저는 제가 증기기관과 유사한 기계를 다루고 있다는 느낌에 수시로 빠져들곤 했는데 (당연히 이 비유는 이미 유명합니다), 특히 모델에 “압력”을 가해서 거시적인 변화 (가령 평균적인 CTR 개선, 혹은 벡터 군집의 위치 이동) 를 만들어 내는 작업을 할 때가 그랬습니다.

열역학이라는 개념적 프레임워크를 결여한 채 증기기관의 효율을 높여보려는 작업이 장님 길찾기에 불과하듯이, 모델이 왜 동작하는지에 대한 통찰을 결여한 채 모델링 작업을 하는 일은 저에게는 날이 갈수록 소설을 쓰는 일과 비슷하게 느껴졌습니다. 특히 추천 분야의 몇몇 논문들을 읽을 때마다 자꾸만 비린 맛이 났는데, 그 비린 맛의 이유를 가만히 생각해보니 저자들의 사고방식에 미묘한 모순이 있기 때문이었습니다. 원래 모델이 왜 동작하는지도 사실 철저히 이해하지 못하는 상황에서, 단지 모델에 A라는 개선을 가했을 때 정확도가 증가하기 때문에 우리는 A가 모델 동작의 일부를 설명한다고 믿어야 한다는 투의 사고방식이 저의 미감과는 맞지 않았습니다. 혼자서라도 이 비린 맛을 해소해보기 위해 특정한 sequence 하나를 골라 그 위에서 모델의 작동을 분석하는 작업을 거듭 해보기도 했는데, 그 경과가 항상 도중에 묘연해지곤 했습니다. 이는 마치 증기기관의 마법을 설명해보기 위해 열역학이라는 새로운 이론 없이 각 분자들의 움직임을 추적해보려는 시도와 유사했던 것입니다.
어쩌면 모델을 이해해야만 개선할 수 있다는 생각 자체가 딥러닝 시대와 부합하지 않는 생각일지도 모릅니다. 지난 몇 년 간 우리가 배운 사실은, 인간이 아이디어를 내서 모델을 정교하게 설계하는 것보다 그냥 단순하게 모델의 스케일을 키우는 것이 더 마법에 가까운 결과를 내놓는 것처럼 보인다는 사실입니다 (물론 이 또한 다소 위험한 일반화입니다). 그러나 (뒤에서 쓰겠지만) Sequential Recommender 로써의 Transformer 는 우악스럽게 스케일업을 한다고 해서 정확도가 마냥 올라가는 것도 아니라서 (오히려 그 반대에 가깝습니다), 저는 자꾸만 진퇴양난의 심정을 느꼈던 것입니다. 그랬기에 이러한 조류에 맞서서 Transformer 를 “제대로” 해부해보려고 시도하는 Anthropic 의 작업들을 맞닥뜨렸을 때 저는 다소 고무될 수밖에 없었습니다.
그들의 작업은 제가 Sequential Recommender 로써의 Transformer 의 동작을 이해하기 위해 따라가면 좋은 일종의 “결”을 제공하는 것으로 느껴졌기 때문입니다 (기계란 언제나 복합물이고, 복합물은 잘못된 결을 따라 나눌 때 그 본성이 반드시 바뀌어 버리는 사물을 뜻한다고 말해봅시다). 또한 그들의 작업이 완결되지 않은 하나의 도전이라는 사실 자체가 일종의 진정성을 더해주는 것으로 보였습니다.
하여, 앞서 간략하게 소개한 Anthropic 의 작업을 seqrec 에서 그대로 흉내내보기에 이릅니다. 우선 zero layer Transformer 의 경우에 생겨나는 bigram statistics 에 대하여 (저는 임시로 이를 L0 circuit 이라고 불렀습니다) logit 값이 높은 쌍들만 따로 뽑아서 살펴보았습니다 (우리의 경우 단어쌍이 아니라 웹문서쌍을 다루게 될 것입니다). 그 중 ordinality 가 강한 문서쌍들이 눈에 띄기도 했고 (아래 중국 문서들),
관련성 높은 뉴스 문서들이 눈에 띄기도 했습니다.

그 다음, self-attention layer 를 한 층 쌓은 one layer Transformer 를 학습시켜서 Anthropic 이 찾은 QK, OV 회로와 유사한 회로들을 찾아보려고 했습니다 (L1 circuits). 그러나 역시 추천 데이터는 언어 데이터와 특성이 많이 다르다는 사실을 발견하게 됩니다. 예를 들어, 최종 logit 이 L0 logit 과 L1 logit 의 합으로 이루어진다고 할 때 (이는 residual network 때문에 그렇습니다), 만약 L1 circuit 들이 “자기만의 무엇인가”를 배운다면 L0 logit 과 L1 logit 은 각각 정답 아이템을 높게 평가해야 합니다. Anthropic 이 분석한 언어 모델에서 L0 logit 이 bigram stats 를, L1 logit 이 skip-trigram 을 배우고 있었던 것과 마찬가지로요. 그러나 (적어도 라이너 데이터 위에서 학습된) 추천 모델은 상당히 다른 양상을 보여줍니다. L1 logit 만 놓고 보면 정답 아이템이 굉장히 낮게 위치하는 것입니다. 예컨대 아래 예제에서 L1 logit 에서의 정답 아이템 rank 는 161838 입니다. 하지만 흥미로운 것은, L0 logit 만 사용할 때보다 (정답 rank 1231), L0 logit 과 L1 logit 을 합쳤을 때 더 좋은 정확도를 보인다는 사실입니다 (정답 rank 661). 즉, Transformer layer 들은 분명 최종 정확도에 기여하는 무엇인가를 배우고 있긴 합니다만, 언어 모델과 달리 회로들이 생겨나고 있다고 보기는 어려웠습니다. 오히려 최종 유저 벡터를 다른 “적당한” 곳으로 옮겨 놓는 “translation vector” 들을 배우고 있다고 사고해야 더 정확한 것이 아닌가 하는 생각이 자꾸만 들었습니다.
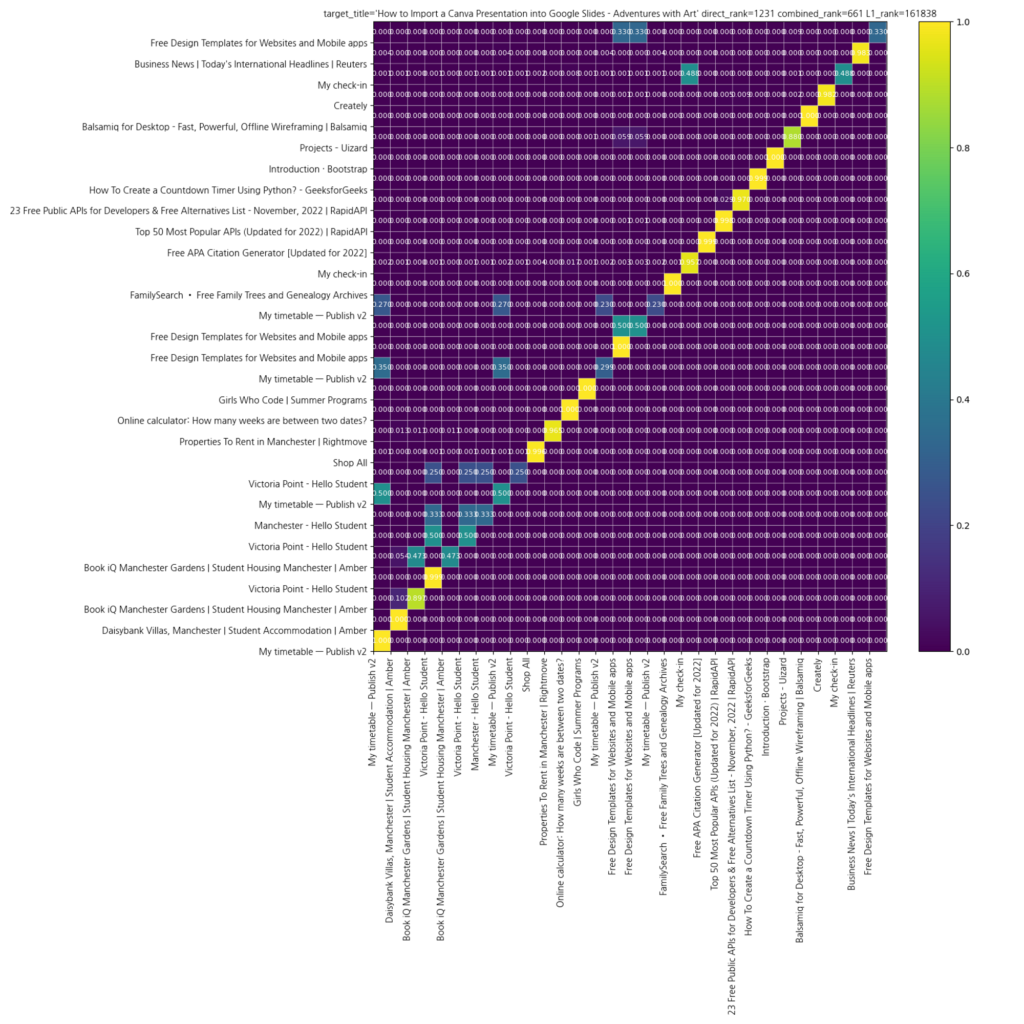
또한 그림의 attention pattern 에서 보듯이, 우리의 attention head 들은 그다지 복잡한 관계들을 배우고 있는 것 같아 보이지 않았습니다. 각각의 query 문서는 이전 히스토리에서 자신과 동일한 (혹은 거의 유사한) 문서들에게만 attend 하는 것으로 보였습니다. 이처럼 모델이 “사실 별 것 배우고 있지 않다” 라는 생각이 들었고, 이를 입증하기 위해 정말 다양한 형태의 모델 변종들을 실험하였습니다. 지면이 부족하여 여기에 다 옮겨적지는 않겠지만, 대체로 저런 생각이 맞았던 것으로 드러났습니다. 예를 들어서 Sequential Recommender 로써의 Transformer 는 layer 수를 증가시켜도 성능이 증가하지 않거나 오히려 하락하는 것으로 관측됐는데, 기존 Sequential Recommender 논문들에서도 (e.g. BERT4Rec) 모델의 최종 layer 수를 2 정도로 보고하는 것을 기억해보길 바랍니다. 그러나 만약 언어모델처럼 “데이터에서 배워낼 것이 많았다”면 모델이 복잡해질수록 성능도 같이 올라갔어야 했을 겁니다. 또 query, key layer 를 사용하는 기존의 attention pattern 대신, 단순히 아이템 간의 timestamp 차이로만 attention weight 를 조절하는 static attention pattern 을 실험해봐도, 경우에 따라 오히려 더 성능이 늘어나는 것으로 관측되었습니다. 앞서 언급한 Anthropic 이 QK 회로와 OV 회로를 분리해서 바라보는 사고방식을 잠시 빌려서 말해보자면, OV 회로는 각 문서의 위치에서 다음 문서를 예측하는 logit 들을 제공하고, QK 회로는 이전 문서들의 logit 들을 어떤 방식으로 “긁어올지”를 결정하는데, 우리의 실험 결과가 말해주는 것은 적어도 우리의 데이터 위에선 QK 회로가 그다지 정교할 필요가 없고 그저 맥락을 “적당히 잘 긁어오기”만 하면 최종 성능에 전혀 무리가 없다는 것입니다.
한 마디로 회로를 찾아 들어간 곳에서 회로는 발견되지 않았습니다. 다소 허무한 결론인가요? 저는 그렇지 않다고 말하고 싶은데, 허무하지 않다는 뜻이 아니라, 결론이 아니라는 뜻에서 그렇습니다. 모델의 단순함은 데이터의 단순함에서 비롯했을 가능성이 높습니다. 우리가 모델을 학습하고 평가해오던 document journey 의 sequence 들을 자세히 들여다보면, 단어들의 나열로 구성되는 언어 데이터에 비해 그 정보량이 상당히 오밀조밀하지 않다는 사실을 발견하게 됩니다. 예를 들어 다음 문서가 현재 문서 이전 맥락에 딱히 의존하지 않거나 (e.g. …A->A), 사용자의 히스토리가 다소 permutation invariant 하거나 (즉, ABABA->A 혹은 BAAAB->A 처럼 순서가 딱히 상관 없음), 아예 엉뚱한 다음 문서가 나오는 경우가 그렇습니다 (e.g. AAAA->C). 우리는 앞서 언급한 작업들을 보다 정교하게 세공된 데이터 위에서 이어나갈 필요가 있습니다.
어떤 사람이 모델링을 잘 한다는 것은 무슨 뜻일까요? 요즘은 그냥 양질의 데이터를 마련하는 것이야말로 작업의 거진 대부분이 아닐까하는 (당연한) 생각이 듭니다. 딥러닝 기계들은 데이터에 내재한 여러 겹의 주름들을 펼칠 수 있는 역량을 제공하는데, 앞서 보았듯이 애초에 펼칠 주름들이 많이 없다면 기계들의 역량은 무용해집니다. 어쩌면 저는 단순히 더 많은 피쳐들을 제안하고 구현하여, 자꾸만 데이터에 주름을 접어 넣는 작업들에 훨씬 더 많은 시간과 에너지를 투자해야 마땅한지도 모릅니다. 가끔씩 꾸는 재밌는 악몽이 있는데, 주식 데이터에서 패턴을 읽어내는 모델을 오랜 기간 개발해오던 제가, 알고보니 모종의 실수로 주식 데이터가 아니라 random walk 데이터 위에서 내내 작업을 해오고 있었다는 것을 깨닫는 악몽입니다 (사실 이런 악몽을 꾼 적은 한번도 없습니다).
Future Work
앞서 살짝 언급했지만, ML 플래닛은 다소 대담한 도약을 준비중입니다. 데이터의 양과 질 두 측면에서 모두 큰 개선이 있을 것으로 기대하고 있습니다. 그 안에서 자발적/비자발적으로 좋은 문제들을 발견하는 데에 성공하여, 제가 이 글에서 벌려놓은 상처들을 봉합하는 내용의 2편을 들고 올 수 있기를 희망합니다.