신뢰성 있는 문서를 골라주기 위한 Liner Ranker
Intro
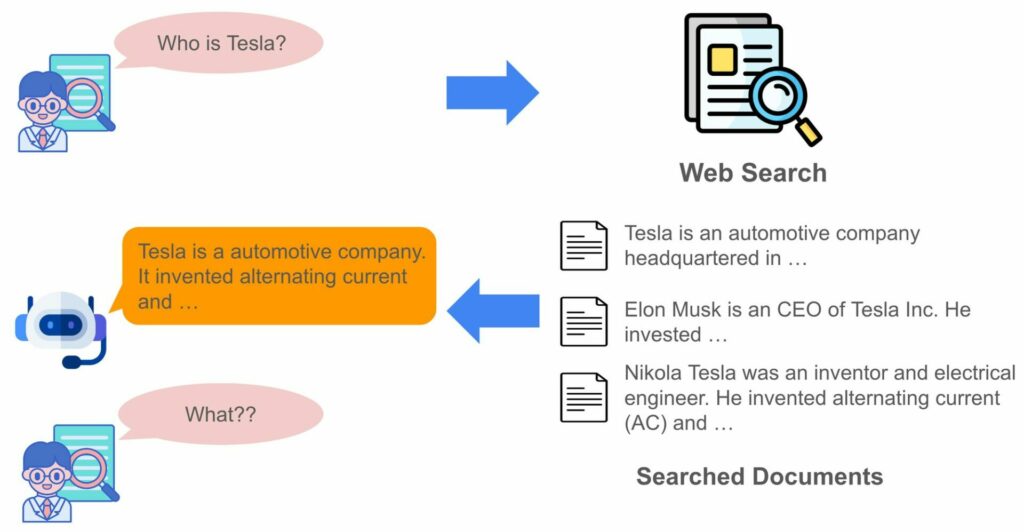
지금까지 LLM은 많은 발전을 해왔지만, 간혹 실제 사실과 다르게 답변하는 Hallucination 문제는 완전히 해결되지 않은 영역으로 남아있습니다. 이것을 해결하기 위해 유저의 질문과 관련된 문서들을 찾고, 해당 문서들의 내용을 기반으로 답변을 생성하는 Retrieval-Augmented Generation (RAG) 기술이 최근 각광을 받고 있습니다. 라이너도 유저가 리서치하면서 생기는 궁금증들을 해소해주기 위해 RAG를 적극적으로 적용하고 있습니다.
이러한 문제들을 해결하기 위해 유저의 쿼리와 문서들간의 관련성을 고려할 필요가 있습니다. 이를 통해서 LLM이 답변을 생성할 때 관련 없는 문서들을 참조 대상에서 배제하고 유저에게 보여주는 출처에도 제외시켜 신뢰성 있는 답변을 제공하는 것이죠. 라이너는 유저 쿼리와 문서들의 관련성을 점수로 계산하고, 이를 기반으로 각각의 문서들의 우선순위를 판단하는 Reranking 방법을 도입하였습니다. 이를 위해 문서의 관련도 점수를 계산하는 랭킹 모델을 학습하는 프로젝트를 진행하여 높은 성능을 내는 Liner Ranker 모델을 만들게 되었습니다.
하지만 RAG도 몇가지 약점이 있습니다. 유저의 쿼리와 관련 없는 문서가 참조 문서 집합에 같이 포함된다면, LLM이 잘못된 참조를 통해 오히려 Hallucination이 강화된다는 문제가 있습니다. 또한, 유저에게 관련 없는 문서를 출처로 보여준다면 유저의 신뢰도 잃게 되죠.
이번 블로그 포스트에서는 Liner Ranker 학습과 관련된 경험과 성과를 공유하고자 합니다.
학습 데이터셋 구축
Ranker 학습을 위해서 고품질의 학습 데이터셋을 구축하는 것이 중요합니다. 특히 두 문서에 대해서 어떤 문서가 더 관련도가 높은지 우열관계를 레이블링하는 작업이 중요한데, 수많은 문서 쌍들에 대해서 사람이 직접 레이블링하는 것은 많은 시간과 비용을 필요로 하게 됩니다. 그렇기 때문에 이번 프로젝트에서는 라이너 자체 데이터에 더해서 LLM 기반의 Automatic-labeling 기법을 활용하여 두 문서의 관련도 우열관계를 결정했습니다.
하지만 LLM이 다양한 영역에서 많은 강점을 보인다고 하더라도, 여전히 특정 도메인이나 태스크들에서 성능이 낮거나 일관성 있게 답변을 하지 않는 경우가 많습니다. 그렇기 때문에 LLM 기반으로 레이블링을 하는 경우 오류를 포함하거나 노이즈가 발생하는 문제가 있을 수 있게 됩니다. 이를 해결하기 위해서 단일 모델로부터 레이블링을 하는 것이 아니라 높은 성능을 보이는 몇개 모델들을 선택하여 여러 모델들로부터 종합적으로 레이블링을 진행하여, 모델의 다양성 강화와 앙상블 효과를 통해 레이블링의 퀄리티를 높이도록 하였습니다. 전반적인 데이터셋 구축 과정은 다음 그림과 같습니다.
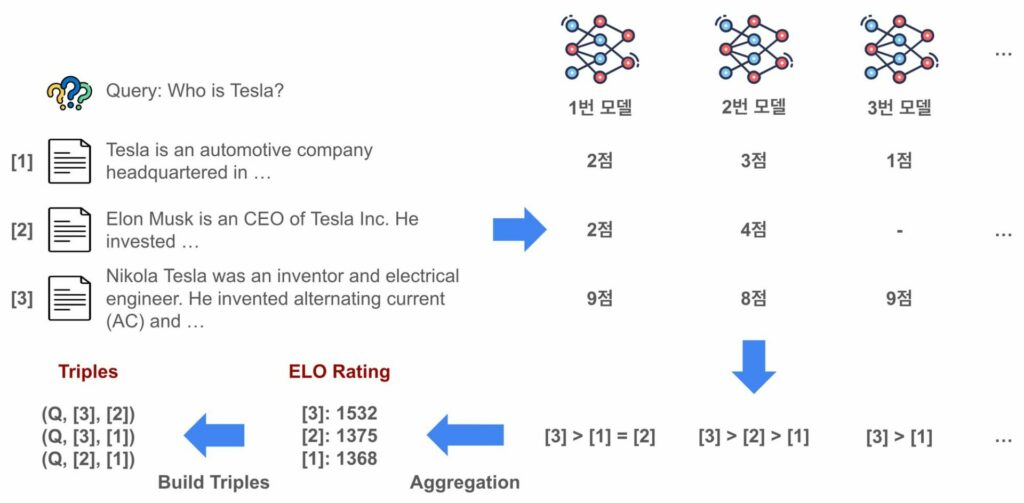
먼저 LLM들로 하여금 쿼리에 대한 각 문서의 관련도 점수를 평가하도록 했습니다. 위 그림에서처럼 1번 모델의 경우 [1]번 문서는 2점, [2]번 문서는 2점, [3]번 문서는 9점으로 평가한 것처럼 말이죠. 이를 기반으로 1번 모델 입장에서 [3] > [1] = [2]라는 문서의 유사도 우열관계를 정할 수 있게 됩니다. 2번 모델과 3번 모델에 대해서도 각각 우열관계를 정하게 되죠. 각 모델로부터 도출된 우열관계를 합산하기 위해 ELO Rating1 방식을 적용하였습니다.
ELO Rating은 원래 체스 선수들의 실력을 수치로 표현하기 위해 제안된 방식으로, 선수들의 승패를 기반으로 점수를 계산하게 됩니다. ELO Rating은 LMSYS Chatbot Arena2 등에서 LLM들의 상대적인 성능 우위를 평가하기 위해서도 사용되고 있습니다. 위 그림과 같이 앞서 LLM들에서 도출한 우열관계들을 기반으로 ELO Rating을 통해 각 문서들에 대한 ELO 점수를 계산하게 됩니다. 이를 통해 최종적으로 [3] > [2] > [1]이라는 종합 우열관계를 도출할 수 있고, 이를 통해 (Query, Positive document 혹은 Win document, Negative document 혹은 Lose document) 형태의 트리플들을 구축할 수 있게 됩니다. 랭킹 모델 학습에는 이 트리플을 사용하게 됩니다.
여기서 간단하게 각 LLM의 점수들을 평균내서 우열관계를 가리는게 아니라, LLM 점수로부터 우열관계를 가리고 다시 ELO 점수 기반으로 최종 우열관계를 가리는 이유는 다음과 같습니다. 먼저 LLM들은 내재적인 편향이 존재할 수 있기 때문에 아무리 프롬프트에 평가 가이드라인을 잘 준다고 하더라도 어떤 LLM은 다소 높은 점수를 내는 경향이 있고, 어떤 LLM은 다소 낮은 점수를 내는 경향이 있을 수 있습니다. 또한, 모델이 잘못된 형식으로 생성하거나 서버 에러 등으로 인해 점수 추출을 하지 못하는 경우가 발생할 수 있습니다. 위 그림의 3번 모델이 2번 문서에 대해서 점수를 판단하지 못한 것처럼 말이죠. 이렇듯 여러 상황들로 인해서 모든 모델이 평가에서 동등한 영향력을 발휘하기 힘들 수 있습니다. 물론 레이블링 자체를 두 문서를 인풋으로 주고 두 문서의 우열관계를 바로 계산하도록 할 수도 있습니다. 하지만 이 경우 모든 문서쌍을 레이블링을 해야하기 때문에 비용과 시간이 매우 많이 들게 됩니다. 그렇기 때문에 라이너는 위와 같은 ELO Rating 방식으로 문서들의 우열관계 평가를 진행했습니다.
더불어 ELO Rating을 통해 A 문서가 B 문서보다 더 관련도가 높은지에 대한 확률을 다음 수식과 같이 계산할 수 있습니다.
$$ P(A \gt B) = \frac{1}{1 + e^{-(R_A – R_B)/s}} $$
이 확률이 커질수록 A 문서가 B 문서보다 쿼리에 대해 훨씬 더 관련성이 크다고 볼 수 있습니다. 해당 확률 정보들을 추후 학습 실험에서 Adaptive margin이라는 개념에 활용하였습니다.
Ranker 학습
이번 Ranker 모델 학습 실험에서는 Meta의 LLAMA 3-8B 모델3을 사용하였습니다. Ranker 학습은 크게 다음 그림과 같은 방식으로 학습을 진행합니다.
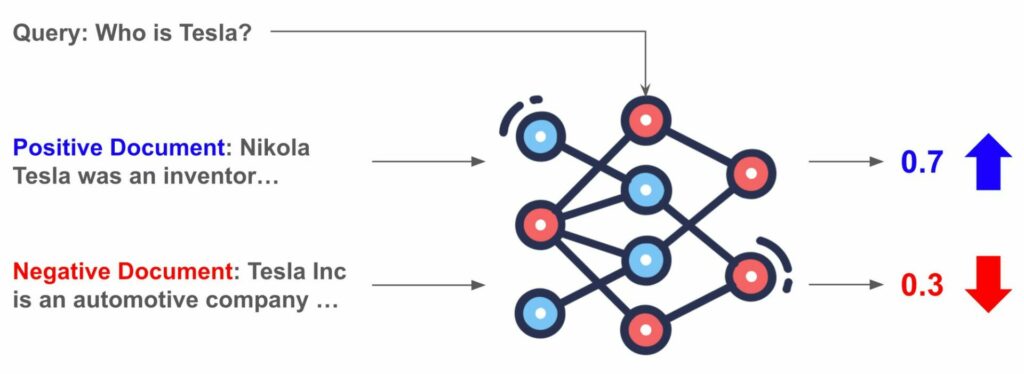
먼저 학습 데이터는 질문(Query), 질문과 관련도가 높은 문서(Positive Document), 질문과 관련도가 낮은 문서(Negative Document)들로 트리플 형태로 구성이 되어 있습니다. 모델은 Query와 Positive Document와 Negative Document를 입력으로 받아 Positive Document가 Negative Document보다 더 관련성이 높을 확률를 계산하게 됩니다. 이러한 확률 모델을 Bradley-Terry model4라고도 합니다.
$$ P_{\theta}(q, d_{pos}, d_{neg}) = \frac{1}{1 + e^{-(f_{\theta}(q, d_{pos}) – f_{\theta}(q, d_{neg}))}} $$
그리고 다음 수식과 같이 Cross Entropy Loss를 통해 모델의 학습을 진행합니다. 이를 통해 Positive document의 점수가 Negative document의 점수보다 커지도록 모델을 학습하게 됩니다.
$$ L = {\mathbb{E}}_{(q, d_{pos}, d_{neg}) \in D}\biggr[ -\log(P_{\theta}(q, d_{pos}, d_{neg}))\biggr] $$
Ranking Loss를 통해서 모델은 positive document의 점수가 negative document의 점수보다 점수가 커지도록 학습이 되게 됩니다.
모델을 최종적으로 학습하기 전에 먼저 두가지 실험을 진행을 했고, 이를 통해 효과적으로 성능을 향상시킬 수 있었습니다. 아래 그 방법에 대해서 설명하고자 합니다.
Adaptive Margin
LLAMA 25 논문에서는 리워드 모델을 학습할 때, 다음 수식과 같이 두 답변의 선호도 차이에 따라 margin을 다르게 주는 것을 제안하였습니다.
$$ L_{ranking} = -\log(\sigma(r_\theta(q, y_c) – r_\theta(q, y_r) – m(r))) $$
여기서 \(m(r)\)은 선호도에 따른 margin 함수로서, 두 답변 \(y_c\)와 \(y_r\)의 선호도 차이가 명확하게 크면 margin 값을 크게 주고, 명확하게 차이가 나지 않는다면 margin 값을 작게 주게 됩니다. 이렇게 가변적으로 margin 값을 다르게 할당함으로써 리워드 (랭킹) 모델의 성능도 높일 수 있게 됩니다.
라이너도 해당 방법론을 적용하여 실험을 진행하였습니다. 앞서 데이터셋 구축 방식을 소개하면서 ELO Rating을 통해 두 문서 사이의 우열관계 확률 \(P(A \gt B)\)를 계산할 수 있다고 설명드렸었습니다. 해당 확률을 기반으로 확률이 큰 경우 margin을 크게 주고, 확률이 작은 경우 margin을 작게 주는 방식으로 Adaptive margin을 적용하였습니다.
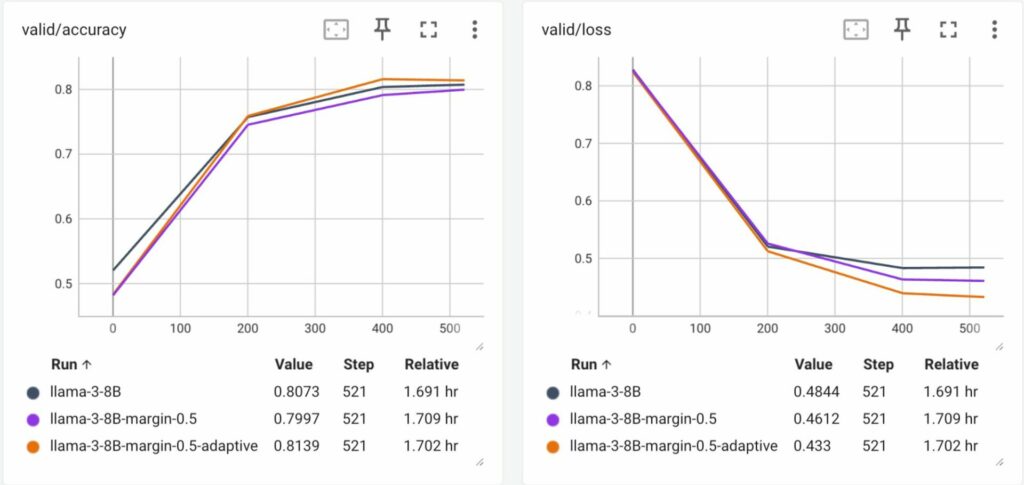
학습 데이터셋의 일부를 이용해서 실험을 진행한 결과, 아래 그림과 같이 margin을 아예 적용하지 않고 학습한 baseline 모델과 margin을 constant하게 할당해서 학습한 모델에 비해 adaptive margin을 적용한 모델의 validation accuracy와 loss 기준에서 성능이 훨씬 더 좋은 것을 확인할 수 있었습니다.
Layer-wise Pruning
일반적으로 Causal Language Modeling을 이용해서 사전학습한 LLM들은 하부 레이어들은 인풋 문장에 대해 의미론적으로 이해하는 역할을 담당하고, 상부 레이어들은 다음 토큰을 예측하거나 생성하는 역할을 주로 담당하는 것으로 알려져 있습니다6. 하지만 리랭킹의 경우 주어진 쿼리와 문서와의 연관성을 고려하는 태스크이기 때문에, 생성 태스크와는 방향이 다를 수 있습니다. 그렇기 때문에 상부 레이어들은 랭킹 모델 학습에서 불필요하거나 학습에 도움이 안될 수 있습니다. 그래서 이번 실험에서는 LLAMA-3 8B 모델의 상부 레이어를 제거하여 32개 decoder 레이어들 중 24개 레이어들만 사용하도록 해서 학습을 진행하였습니다. 실험 결과는 다음과 같습니다.
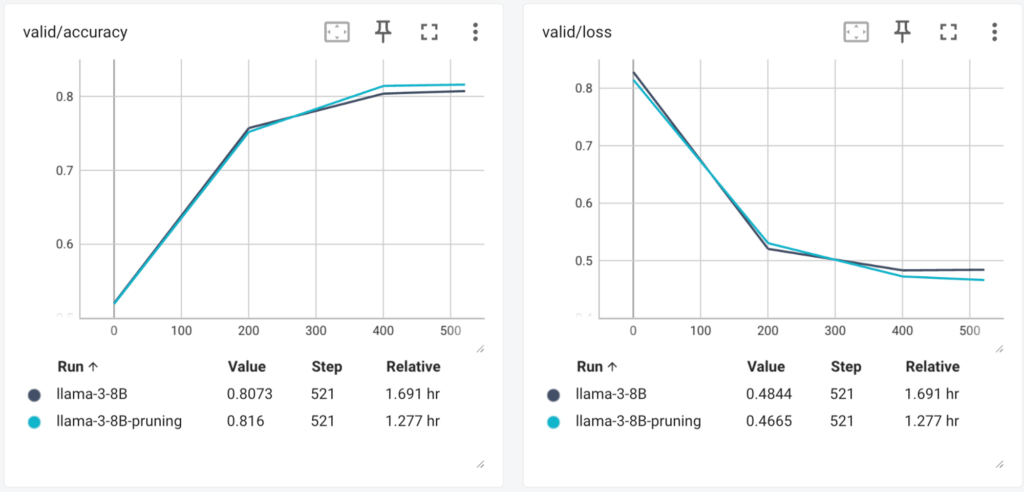
놀랍게도 Validation accuracy 및 loss가 전체 레이어들을 사용하는 것에 비해 하위 24개 레이어들만 사용하는 것이 성능이 더 좋은 것을 확인할 수 있었습니다. 이는 다음 토큰을 예측하는 태스크를 신경쓰지 않고 온전히 인풋 문장을 이해하는 능력을 기반으로 랭킹 모델을 학습할 수 있었기 때문입니다. 특히 모델 사이즈도 7.5B(랭킹 모델은 마지막 lm_head layer 대신 classification head로 대체하기 때문에 8B에서 7.5B로 감소)에서 5.76B로 약 23%를 줄여 경량화할 수 있었습니다. 이를 통해서 모델이 필요로하는 GPU 메모리 및 학습/추론 시간도 최적화할 수 있었습니다.
최종 학습
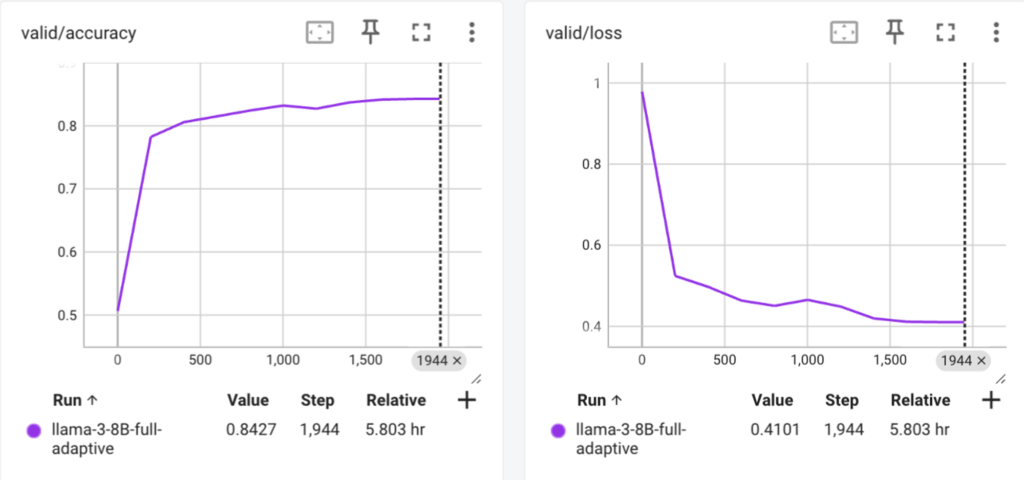
앞서 실험한 Adaptive Margin과 Layer-wise pruning 방식을 적용하여 학습 데이터셋을 전부을 사용하여 학습을 진행하였습니다. 학습에는 FSDP7를 적용하였고, A100 80GB 8대의 서버에서 학습을 진행하였습니다. 최종 학습 결과는 다음과 같습니다.
평가
학습한 모델의 성능을 평가하기 위해서 라이너는 MTEB8과 BEIR9 벤치마크를 이용해서 평가를 진행하였습니다. 이때, MTEB의 경우 Reranking 태스크만을 평가하였고, MindSmallReranking의 경우 문서 집합 크기가 너무 커서 평가가 너무 오래 걸리기 때문에 Jina Rerank10 블로그에서 평가한 것과 같이 제외하였습니다. BEIR의 경우 7개의 카테고리와 공개된 14개의 데이터셋(Fact Checking (Fever, Climate-Fever, Scifact), Question Answering (NQ, HotpotQA, FiQA), Bio-Medical IR (TREC-COVID, NFCorpus), Argument Retrieval (Webis-douche 2020, Arguana), Duplicate-Question Retrieval (Quora, CQADupStack), Citation Prediction (Scidocs), Entity Retrieval (DBPedia-Entity)에 대해서 평가를 진행하였고, 각 카테고리별로 성능을 측정하였습니다. 이 때 BEIR의 경우 문서 집합이 매우 크기 때문에 랭킹 모델을 평가하는 것은 매우 시간이 오래 걸릴 수 있습니다. 따라서 Cohere Ranker11에서 모델을 평가한 방식을 활용하여, 먼저 BM25를 이용해 쿼리와의 연관성이 높은 100개 문서를 뽑은 뒤 100개 문서들에 대해서 Ranking 모델이 리랭킹을 적용하여 상위 10개 문서에 대한 nDCG(Normalized Discounted Cumulative Gain)를 평가하였습니다.
또한 다른 리랭킹 모델들과도 성능을 비교하기 위해 상업용 모델들인 Cohere-Rerank-English-v3와 Jina-reranker-v1-base-en과 MTEB Leaderboard12 상에서 높은 성능을 보이고 있는 BGE-Large-en-v1.513과 GTE-Qwen2-7B-Instruct14을 비교 모델로 사용하여 동일한 테스트 환경에서 성능을 비교하였습니다. 참고로 이번 랭커 학습에는 외부 공개 데이터셋을 전혀 사용하지 않았습니다. 그렇기 때문에 BEIR 및 MTEB 벤치마크 데이터셋 중 학습 데이터셋이 같이 공개된 경우에 대해서는 다른 모델들이 해당 학습 데이터셋들을 학습되었을 수 있기 때문에 라이너 랭커가 상대적으로 불리할 수 있습니다.
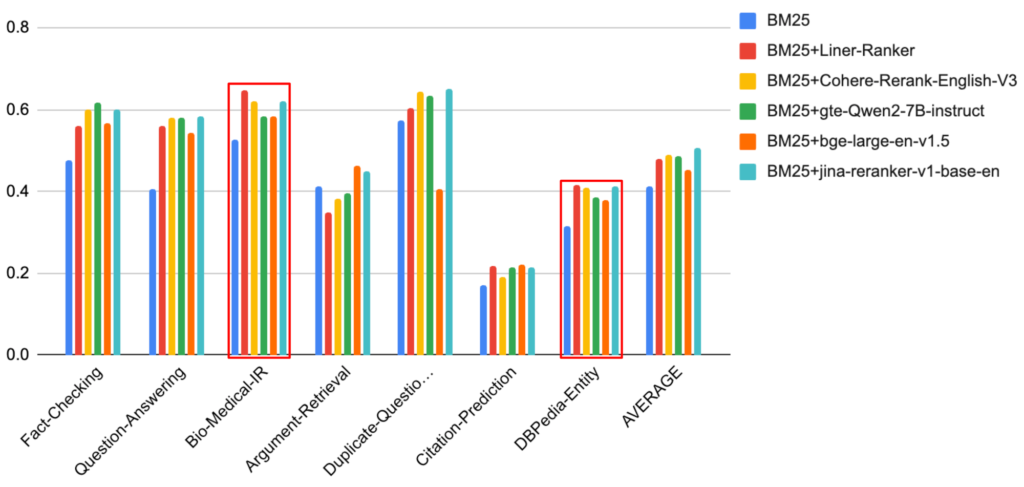
먼저 BEIR의 평가 결과는 아래 차트와 같습니다. 전반적으로 Liner-Ranker의 리랭킹 성능이 Cohere Rerank와 bge-large-en-v1.5의 성능과 비슷한 것을 알 수 있습니다. 특히 Bio-Medical과 DBPedia-Entity 카테고리에서는 다른 모델들에 비해서 성능이 더 높은 것을 볼 수 있습니다.
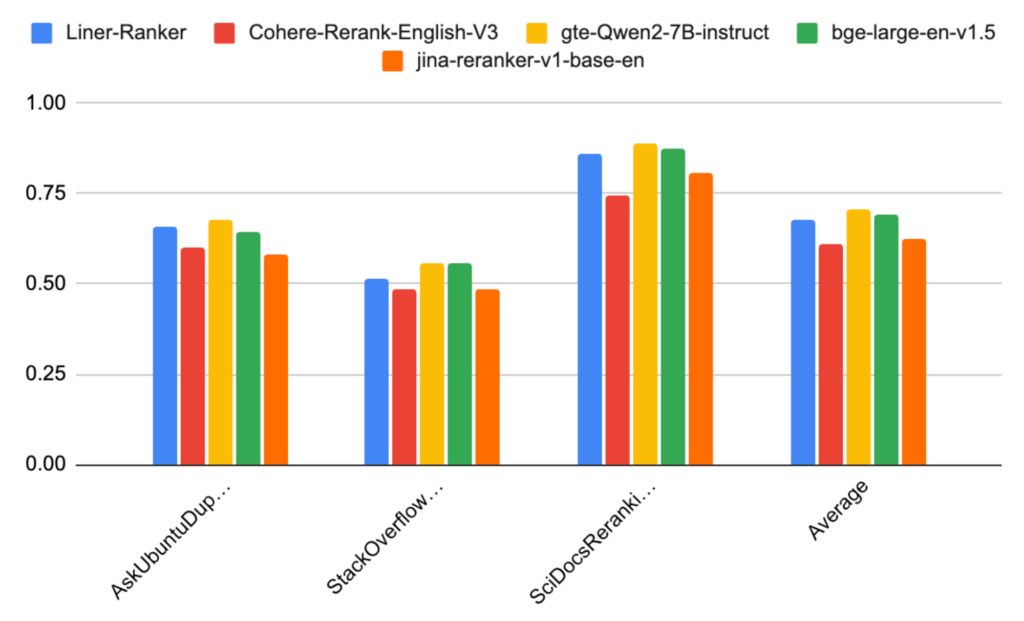
MTEB Reranking 벤치마크의 성능은 아래 차트와 같습니다. 전반적으로 현재 MTEB 리더보드에서 SoTA 모델 중 하나인 gte-Qwen2-7B-instruct 및 bge-large-en-v1.5와 비교해 보아도 준수한 성능을 보이고 있는 것을 볼 수 있습니다. 특히 상업용 모델인 Cohere-Rerank와 Jina-reranker보다 성능이 더 높은 것을 볼 수 있습니다.
마치며
이번 랭킹 학습 프로젝트를 통해서 랭킹 모델 학습 데이터셋 구축부터 학습까지 자체적으로 진행을 하였습니다. 특히 LLM 기반의 Automatic-Labeling과 Adaptive margin, layer-wise pruning을 적용하여 랭킹 모델의 성능을 높이고 효율까지 개선할 수 있었습니다. 또한 MTEB과 BEIR 벤치마크 평가를 통해서 이번에 Liner에서 학습한 랭커 모델이 다른 최신 랭킹 모델들과 종합적으로 비교했을때도 경쟁력 있는 성능을 보여주는 것을 확인할 수 있었습니다.
라이너가 학습한 랭킹 모델은 현재 Liner 서비스에 적용되어 있으며, 다음 “Who is Tesla?” 예시와 같이 유저 질문과 관련 없는 문서의 순위를 낮추고 참조하지 않도록 하여 유저의 신뢰성을 확보하는 파수꾼 역할을 담당하고 있습니다 😊
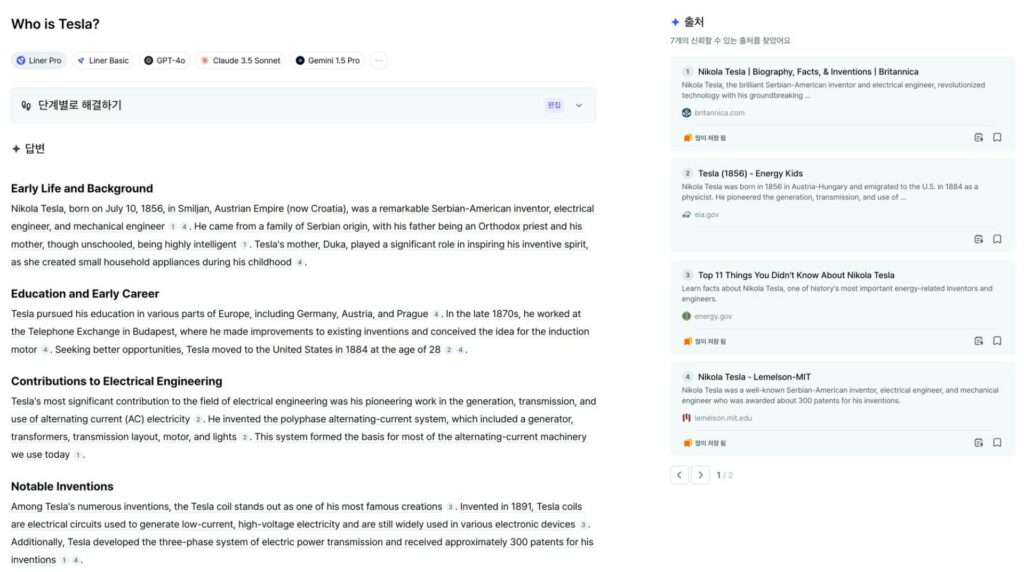
물론 라이너 랭커의 성장은 여기서 멈추지 않았습니다! 다양한 외부 공개 데이터셋 및 양질의 라이너 데이터를 안전하게 활용하고, 전반적인 학습 과정을 개선하여 모델의 성능을 훨씬 더 높이고 강건하게 할 예정입니다. 현재 랭커의 성능을 개선하고, 부적절한 문서를 필터링을 담당하는 랭킹 담당 ML 엔지니어를 모집하고 있습니다. 라이너 유저의 리서치 활동에 도움이 되는 라이너 랭커를 연구하는데 관심이 있으시다면 지원하셔서 저희와 의미 있는 도전을 같이 할 수 있기를 기대합니다! 😄
참고 문헌
- ELO Rating
Elo, Arpad E. “The proposed uscf rating system, its development, theory, and applications.” Chess life, 1967.
https://en.wikipedia.org/wiki/Elo_rating_system ↩︎ - LMSYS Chatbot Arena
https://chat.lmsys.org/?leaderboard ↩︎ - Meta LLAMA-3
https://llama.meta.com/llama3/
https://huggingface.co/meta-llama/Meta-Llama-3-8B ↩︎ - Bradley-Terry Model
https://en.wikipedia.org/wiki/Bradley–Terry_model ↩︎ - Touvron, Hugo, et al. “Llama 2: Open foundation and fine-tuned chat models.” arXiv:2307.09288 (2023).
https://arxiv.org/abs/2307.09288 ↩︎ - Liu, Zhu, et al. “Fantastic Semantics and Where to Find Them: Investigating Which Layers of Generative LLMs Reflect Lexical Semantics.” arXiv:2403.01509 (2024).
https://arxiv.org/abs/2403.01509 ↩︎ - Zhao, Yanli, et al. “Pytorch fsdp: experiences on scaling fully sharded data parallel.” arXiv:2304.11277 (2023).
https://arxiv.org/abs/2304.11277 ↩︎ - Muennighoff, Niklas, et al. “MTEB: Massive Text Embedding Benchmark.” Conference of the European Chapter of the Association for Computational Linguistics. 2023.
https://aclanthology.org/2023.eacl-main.148 ↩︎ - Thakur, Nandan, et al. “BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models.” Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
https://openreview.net/forum?id=wCu6T5xFjeJ ↩︎ - Jina Reranker
https://jina.ai/news/maximizing-search-relevancy-and-rag-accuracy-with-jina-reranker/ ↩︎ - Cohere Rerank
https://cohere.com/blog/rerank-3 ↩︎ - MTEB Leaderboard
https://huggingface.co/spaces/mteb/leaderboard ↩︎ - BGE-Large-en-v1.5
https://huggingface.co/BAAI/bge-large-en-v1.5 ↩︎ - GTE-Qwen2-7B-Instr
https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct ↩︎


