양질 중 우선시 되어야 하는 것은? Quality!
개요
안녕하세요, 머신러닝 엔지니어로 근무 중인 카터입니다! 이번 포스트에서는 세상에 존재하는 모든 텍스트 컨텐츠가 적재될 수 있는 라이너에서 사용자에게 양질의 추천을 제공하기 위해 컨텐츠 필터링을 어떤 식으로 수행하고 있는지, 그리고 앞으로 어떻게 발전시키고자 하는지에 대해 소개드리고자 합니다.
라이너는 사용자의 텍스트 하이라이트 이벤트를 추천 모델링을 위한 사용자 피드백으로 적극 활용하고 있습니다. 라이너에 초기 탑승한 사용자들은 대개 라이너 익스텐션을 본인의 학습 및 업무에 도움이 될 수 있는 컨텐츠에 하이라이트를 하기 위해 활용했습니다. 때문에 로그를 통해 적재되는 피드백 역시 생산적인 컨텐츠에 편중되었습니다. 이를 통해 개발, 의학, 경제 등 다양한 생산적인 주제의 컨텐츠들에 대한 양질의 피드백이 적재될 수 있었죠.
그러나 서비스 발전 과정에 따라 사용자 모수가 커지게 되고, 초기 열성 사용자가 익스텐션을 통해 제공해주던 양질의 피드백을 모든 사용자에게 기대할 수는 없게 되었습니다. 라이너를 사용해 기상천외한 곳들에 하이라이트를 남기는 사용자들이 등장하기 시작했던 것인데요. 성인 사이트는 물론이고, 색채가 지나치게 강한 종교 사이트, 배달 사이트에 등록된 음식점 등 일반적인 사용자에게 쉽게 추천해주기 어려운 컨텐츠들에 대한 사용자 피드백이 나날이 늘어나기 시작했습니다.

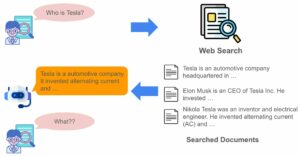
이에 따라 컨텐츠 필터링은 자연스레 라이너가 해결해야 할 중요한 과제로 떠오르게 되었습니다. 추천 시스템에서는 일반적으로 위 그림과 같은 세 개 단계를 거쳐 사용자에게 아이템을 추천하게 됩니다. 그리고 컨텐츠 필터링은 위 과정 중 Candidate Generation과 Scoring 사이에 속하게 됩니다. 이는 컨텐츠에 대한 이해를 통해 추천 대상이 될 수 있는 아이템을 미리 선별해두는 과정을 총칭합니다.
그렇다면 앞서 소개드린 문제는 어떻게 해결할 수 있을까요? 라이너는 컨텐츠를 발행하는 사이트 도메인 자체에 대한 신뢰를 기반으로 한 컨텐츠 품질 판단에 집중해보았습니다.
Popularity Bias의 사이드 이펙트 누리기
추천 시스템이 겪는 고질적인 어려움 중 하나로 Popularity Bias가 있습니다. 이는 이름 그대로 유명한 아이템들에 편향이 낄 수 있다는 의미로, 플랫폼 내 인기 아이템들에만 사용자 피드백이 지속적으로 쌓여 그 결과 추천의 후보가 되는 기준이 아이템의 Popularity에 의존하게 되는 문제입니다.
그렇다면 Popularity Bias는 항상 부정적 편향으로만 해석되어야 할까요? 상황에 따라 그럴수도, 그렇지 않을 수도 있습니다. 우리는 Popularity Bias를 긍정적으로 해석했을 때 얻을 수 있는 이점을 살펴보았습니다. 라이너 플랫폼에서 컨텐츠의 Popularity가 높다는 것은 많은 사용자가 해당 컨텐츠에서 하이라이트 액션을 수행했다는 의미입니다.
그리고 이러한 Popularity를 개별 컨텐츠가 아닌 컨텐츠를 발행한 도메인으로 확장하게 되면 사용자가 하이라이트 액션을 많이 수행한 Popular 사이트를 파악할 수 있게 됩니다. 바로 이 부분에서 문제를 해결할 실마리를 발견할 수 있었습니다.
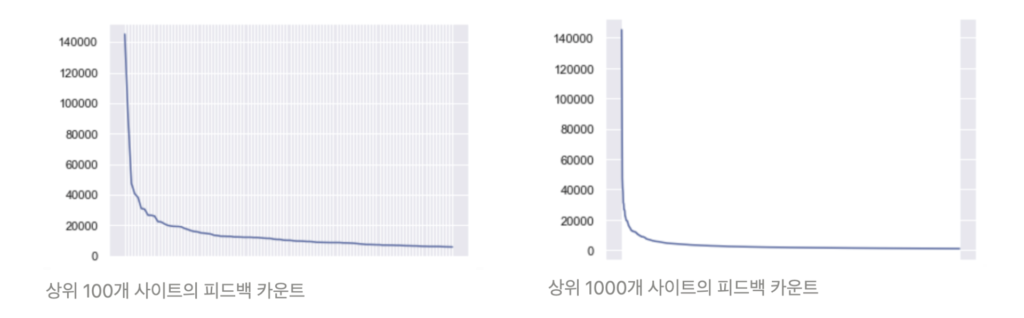
먼저 사용자의 하이라이트 액션 순으로 도메인들의 Popularity를 정렬한 결과, 대부분의 플랫폼에서 나타나는 Short Head, Long Tail의 그림이 라이너에서도 확연히 나타나는 것을 확인할 수 있습니다. 그리고 그 중에서도 Wikipedia, ResearchGate, Medium 등을 포함한 상위 100개 도메인의 Popularity가 특히 두드러지게 나타났습니다.
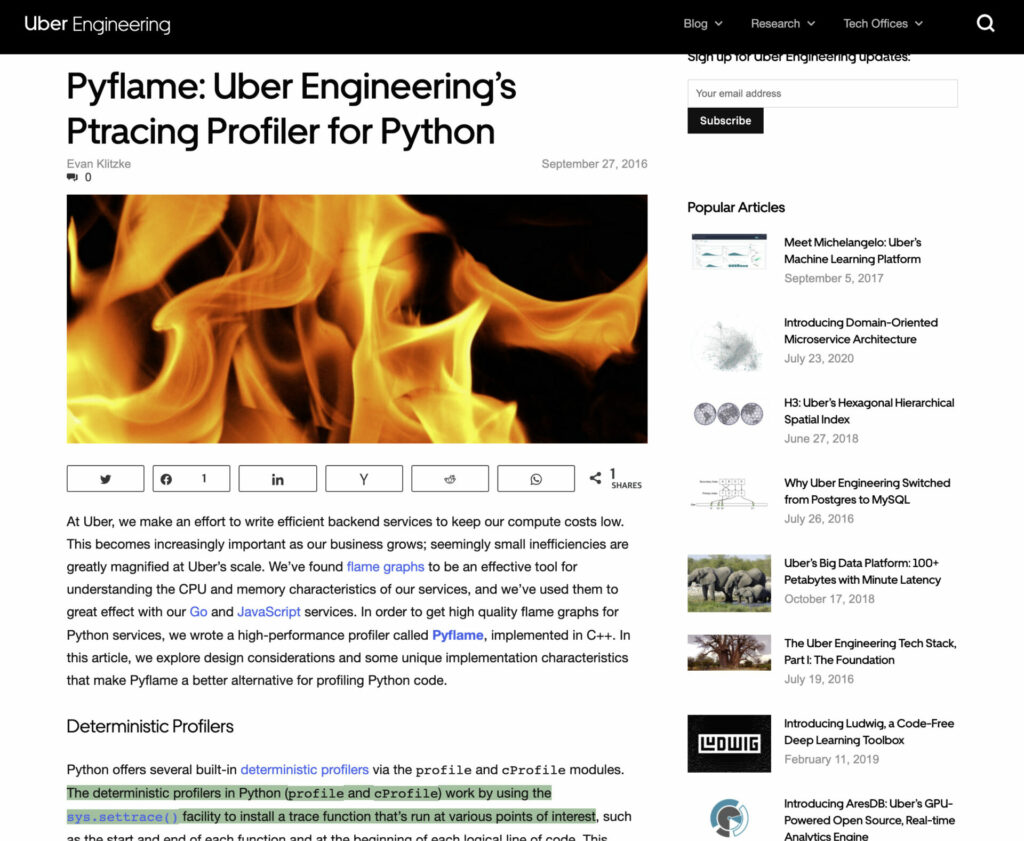
이후 Short Head에 속한 도메인들을 샘플링하여 관찰해보니, 많은 도메인들이 자체적으로 컨텐츠 퀄리티 컨트롤을 수행하는 곳이었습니다. 여기서 개별 컨텐츠를 신뢰하는 것이 아니라, 컨텐츠를 발행하는 도메인을 신뢰하는 방식으로 필터링 로직을 구축할 수 있겠다는 안을 떠올리게 되었습니다.
하지만 Short Head에 속했다는 이유만으로 도메인들을 모두 신뢰할 수는 없었기에 우리가 신뢰할 수 있다고 규정할만한 조건을 선정한 후, 어노테이션 가이드라인을 작성하였습니다. 이후, 어노테이터와의 소통 및 협업을 통해 Trustable 도메인 리스트를 구축할 수 있었습니다.

위 과정을 통해 최종적으로 거인의 어깨 위에 올라타 퀄리티 컨트롤을 잘 수행하는 Popular 도메인 자체를 신뢰해 해당 도메인에서 생산한 컨텐츠는 믿을 수 있다고 판단해 사용자에게 추천을 해주는 방식으로 로직을 구축하게 되었고, 현재 서비스에까지 적용하게 되었습니다.
이번 로직은 단순한 아이디어에서 출발한 개선안이었지만, 실제로 해당 필터링 적용 이후 추천되는 컨텐츠의 퀄리티가 많이 개선되었고 지나치게 튀는 도메인들의 컨텐츠가 추천 후보군에서 배제되어 사용자 선호에 부합하는 컨텐츠를 추천하기 더 용이해졌습니다.
문제를 일부 해결하기는 했지만, 아직 해결해야 할 과제는 여전히 많이 남아있습니다. 앞으로 라이너가 컨텐츠 필터링에 있어 어떤 문제를 해결하고자 하는지에 대해 짤막하게 소개드리겠습니다.
앞으로의 과제
위에서 이야기한 바와 같이 라이너는 컨텐츠 필터링을 위해 의도적으로 Short Head에 진입해 컨텐츠 추천을 하기로 결정했습니다. 해당 의사결정에 있어 주요했던 포인트는 “사용자에게 추천되면 좋을 컨텐츠가 추천되지 못한 경우”와 “사용자에게 추천되면 안되는 컨텐츠가 추천된 경우”를 사용자 경험 관점에서 비교해보는 것이었고, 전자가 차악(?)이라는 결론에 이르어 해당 결정을 내리게 되었습니다.

그렇다면 남은 문제는 너무나도 명확합니다. Long Tail에 속하는 좋은 컨텐츠를 양지로 끌어올려와야 하는 것이죠. 이는 사용자 피드백만으로는 해결할 수 없는, 컨텐츠 자체의 퀄리티를 판단할 수 있는 기술과 함께 풀어야 하는 숙제이자, 라이너가 양질의 추천 후보군을 지니기 위해 반드시 풀어야 하는 영역이기 때문에 다음 분기부터 본격적으로 집중해보고자 합니다.
다음으로 라이너는 올해 7월 YouTube 하이라이트 기능을 출시하기도 했습니다. 시청하고 있는 동영상에서 원하는 지점에 타임스탬프를 찍어 기록을 남길 수 있도록 도와주는 본 기능을 통해, 현재 라이너에는 수많은 동영상 데이터 역시 적재되고 있습니다.

당연하게도 YouTube 하이라이트를 통해 적재되는 데이터 역시 필터링을 필요로 하는 부분이 많이 존재합니다. 텍스트 하이라이트로 시작한 라이너는 텍스트 관련 노하우를 많이 보유하고 있지만, 동영상에 대한 이해에 관해서는 부족한 부분이 많습니다. 때문에 기존 인력들의 텍스트 관련 노하우와 채용을 통해 해당 문제를 해결하고자 하고 있습니다.
지금까지 라이너가 성장궤도에 오름에 따라 겪게 된 문제 상황과 이를 해결하기 위해 취한 조치, 앞으로 해결해야 할 관련 과제들에 대해 소개를 드렸습니다. 해당 문제를 비롯해 라이너에는 아직 해결해야 할 숙제가 많이 남아있기 때문에 더 다양한 문제를, 더 깊이있게, 직접 해결하고자 하는 분들은 언제든 문을 두들겨주셨으면 좋겠습니다.
WANTED: 데이터로 라이너를 더 단단하게 만들어 주실 분
라이너는 전 세계 300만 사용자와 함께 하는 하이라이팅 기반 정보 탐색 서비스입니다. 기존 텍스트 하이라이트에 YouTube 하이라이트까지 등에 업은 라이너에는 매일 텍스트와 동영상 등 다양한 모달리티의 컨텐츠에 대해 수백만 건의 로그 데이터가 쌓이고 있습니다.

라이너는 데이터를 활용해 사용자가 원하는 발전을 위해 소비해야 할 컨텐츠를 추천해주는 탐색의 역할을 대신해주고자 합니다. 라이너가 해결하고자 하는 문제를 풀어줄 모델링을 하고 싶은 머신러닝 사이언티스트, 추론 엔진을 300만 사용자에게 쾌적하게 서빙해보고 싶은 머신러닝 엔지니어, 외에도 데이터를 과학적으로 혹은 엔지니어링적으로 잘 다루시는 모든 분들을 기다리고 있습니다!