Bag-of-Tricks for Recommendation: Recency, Clustering 그리고 Item Shuffling

안녕하세요, 머신러닝 엔지니어 카터입니다. 추천 시스템을 프로덕트에 적용하게 되면 이전에는 볼 수 없었던 수많은 문제점들이 보이기 시작합니다. 이번 글에서는 제가 라이너 추천 시스템을 개발하며 마주했던 문제 사항들과 해당 문제들을 해결하기 위해 적용한 방법론들에 대한 이야기를 드리고자 합니다.
Recency: 최신성 고려하기
첫 번째 문제는 콘텐츠의 최신성에서 시작되었습니다. 엔지니어인 저는 주로 개발 콘텐츠를 소비합니다. 때문에 오래 전 발행된 아티클을 마주하는데 큰 불편함을 느끼지 못했습니다. 과거에 발행된 아티클을 통해 겪고 있던 이슈를 해결했던 숱한 경험들 때문이겠죠.
하지만 모든 사용자가 “최신성이 (크게) 고려되지 않아도 되는 콘텐츠”만 소비하는 것은 아닙니다. 최신 경제 뉴스를 스크랩하기 위한 용도로 라이너를 활용하는 사용자 분도 계실테고, 크립토 소식을 기록하는 사용자도 계실테며, 보다 가까운 예로 라이너 팀 동료 벤은 투자 관련 시사 뉴스를 기록하기 위해 라이너를 활용하고 있기도 합니다.
추천 시스템을 개발하며 팀원들의 피드백을 받던 중, 벤에게 2018년 뉴스가 추천되고 있다는 사실을 알게 되었습니다. 그리고 벤과 같이 시의성(Time-sensitivity)이 중요한 콘텐츠들을 주로 소비하는 사용자 군을 위해 최종 추천 순위에 최신성(Recency)을 반영할 수 있는 Re-ranking의 적용을 고려해야 한다는 사실을 실례를 통해 깨닫게 되었습니다.
이렇게 굉장히 당연해보이고 일반적인 문제를 마주한 후, 관련 자료를 찾아보니 “추천 시스템에 있어 최신성은 고려되어야 한다”와 같은 시시콜콜한 이야기만 나오고 명쾌한 해결안을 발견하지는 못했습니다. 일부 타임스탬프 값을 모델링에 활용하는 사례를 찾기는 했지만, 이는 지나치게 복잡했습니다.
그렇게 소득 없는 리서치를 마친 후, 제가 내린 결론은 Information Retrieval (이하 IR) 분야에서 서로 다른 모델로부터 도출된 문서 리스트를 Aggregate하기 위해 활용하는 Reciprocal Ranking Fusion을 도입하는 것이었습니다.

Reciprocal Ranking Fusion은 이해하기 매우 직관적일 뿐만 아니라, 구현도 어렵지 않았기 때문에 Recency를 고려하기 위한 Re-ranking 로직 구현에 적합하다고 판단하였습니다. 모델이 내놓은 추천 목록과 최신 시간순으로 정렬된 추천 목록에 각각 가중치를 부여하고 결과만 Aggregate하면 되기 때문에 매우 쉽게 구현할 수 있었죠!
그렇다면 시간순 정렬을 위해서는 어떤 정보를 활용하는게 가장 바람직할까요? 당연히 콘텐츠가 발행된 시간일 것입니다. 라이너는 해당 정보를 published_at 이라는 필드로 저장하고 있습니다. 하지만, published_at 에는 한 가지 단점이 있었는데 바로 NA 값이 존재할 수 있는 필드라는 점입니다. 웹 상에 모든 콘텐츠가 발행일자를 메타 태그로 잘 기록해두고 있지는 않기 때문에, NA 값이 존재했고 따라서 해당 필드를 정렬에 활용할 수는 없었습니다.
때문에 차선책으로 last_scrapped_at 이라는 필드를 활용했습니다. 해당 필드는 특정 콘텐츠가 최근 하이라이트 된 날짜를 기록하기 위해 존재합니다. 조사한 바에 따르면 YouTube는 최신성을 고려하기 위해 동영상 업로드 일자와 최근 시청 일자를 활용한다고 합니다. 따라서 이를 라이너 식으로 치환해 최근 하이라이트 일자를 피쳐로 활용하기로 결정했습니다. 위 과정을 코드로 보면 아래와 같습니다.
func ReciprocalRankFusion(candidatesPerModels []CandidatesPerModel) []EsDocument {
documents := make(map[string]EsDocument)
for _, candidatesPerModel := range candidatesPerModels {
for _, document := range candidatesPerModel.Candidates {
documents[document.id] = document
}
}
scores := make(map[string]float32)
for _, candidatesPerModel := range candidatesPerModels {
for rank, candidate := range candidatesPerModel.Candidates {
scores[candidate.id] += 1 / (candidatesPerModel.Weight + rank)
}
}
...
}
...
// sort by recency score
recentDocuments := SortByRecentAction(recommendedDocuments)
recencyRank := CandidatesPerModel{
Candidates: recentDocuments,
Weight: RecencyWeight,
}
normalRank := CandidatesPerModel{
Candidates: recommendedDocuments,
Weight: NormalWeight,
}
result = ReciprocalRankFusion([]CandidatesPerModel{recencyRank, normalRank})라이너는 해당 로직의 적용을 통해 최신성이 고려된 추천 목록을 제공할 수 있게 되었습니다. 추천 문서 목록과 최신 문서 목록 간 가중치는 운영상 조정될 수 있는 값이며, 라이너의 경우 각각 1.0, 0.9로 설정하였습니다. 즉, 최신 문서 목록의 순위가 최종 Aggregate 결과에 더 영향을 많이 미치게 설정했습니다. (가중치는 분모에 적용되기 때문에 작을수록 스코어에 더 큰 영향을 주게 됩니다.)
최신성을 고려할 수 있도록 Re-ranking 로직을 고안하긴 했지만 앞서 엔지니어인 제 사례를 들려드린 것처럼 모든 사용자가, 모든 컨텍스트에서 최신성을 고려한 Re-ranking을 요구하지는 않을 수 있습니다. 따라서 향후 Recency 관련 정렬 옵션을 사용자가 직접 결정할 수 있도록 선택권을 부여하는 대안도 고려하고 있습니다.
Clustering: 사용자 히스토리 구분하기
이전 글에서 소개를 드렸지만, 라이너는 콘텐츠 기반 추천 시스템 구축 시 세션 개념을 활용했습니다. 이는 사용자 하이라이트 히스토리를 30분 단위 세션으로 구분하게 되면 유사한 토픽의 글들이 인접쌍으로 엮일 것이라는 가정 하에 내린 설정이었습니다.
그리고 학습 이후, 추론 단계에서는 사용자의 최근 하이라이트 기록 10개를 읽어와 콘텐츠 추천을 위해 활용했습니다. 10개 문서에 대한 임베딩을 구한 후, Mean Pooling을 거쳐 사용자가 관심 있어할 만한 콘텐츠를 추천해주는 개념인 것이죠.
여기서 두 번째 문제를 마주하게 됩니다. 사용자의 최근 하이라이트 기록 10개 문서는 토픽의 개념으로 보았을 때 반드시 유사할까요? 문제 해결 과정에서 제가 내린 결론은 “십중팔구 유사하지 않다”입니다. 저만 하더라도 항상 유사한 토픽의 글들만 읽지는 않으니 말이죠.
즉, 학습 단계와 추론 단계에서 푸는 문제가 달라져 버린 셈입니다. 학습 단계에서는 “30분 내 동일한 사용자가 하이라이트 한 콘텐츠는 유사하다“와 같은 쉬운 문제를 풀던 모델에게 추론 단계에서는, 자 이제 “머신러닝을 좋아하고, 가끔 레시피를 보기도 하며, 인디 밴드를 좋아하는 사용자에게 추천할 만한 글을 가져와봐”라고 요청하는 모습이 되어버린 것입니다. 저는 참 못 된 엔지니어입니다.
이러한 훈련-추론 불일치 문제를 해결하기 위해 클러스터링 단계를 도입했습니다. 먼저 사용자가 최근 하이라이트 한 문서들에 대해 임베딩을 모두 추출한 후, 임베딩 기반으로 클러스터링을 수행합니다. 그리고 추천 모델로 하여금 클러스터 단위로 문서를 추천하도록 합니다. 만약 클러스터가 3개였다면 총 3개 추천 결과 목록이 나오겠죠?
이를 위해 쉽게 수행할 수 있는 KMeans 클러스터링을 적용하였습니다. FastAPI + FAISS 기반의 서버를 띄운 후, 문서 임베딩들을 해당 서버에 보내 클러스터 결과를 반환 받도록 로직을 전개했습니다. 여기서 한 가지 문제에 봉착하였는데, KMeans 클러스터링 수행을 위해서는 항상 몇 개의 클러스터가 존재하는지 k 값을 미리 넘겨줘야 한다는 점입니다.
현재는 numClusters := int(math.Sqrt(float64(len(documents)))) 와 같이 전체 문서 개수에 따라 동적으로 클러스터 개수가 정해지도록 설정했지만, 이는 완전히 바람직한 해결책은 아닙니다. 10개 문서가 모두 동일한 클러스터로 엮일 수 있을 정도로 유사한 문서들인데, 억지로 3개 클러스터로 쪼개 추천을 받는 경우가 생길 수 있기 때문입니다. 따라서 해당 설정은 향후 개선될 필요가 있습니다.
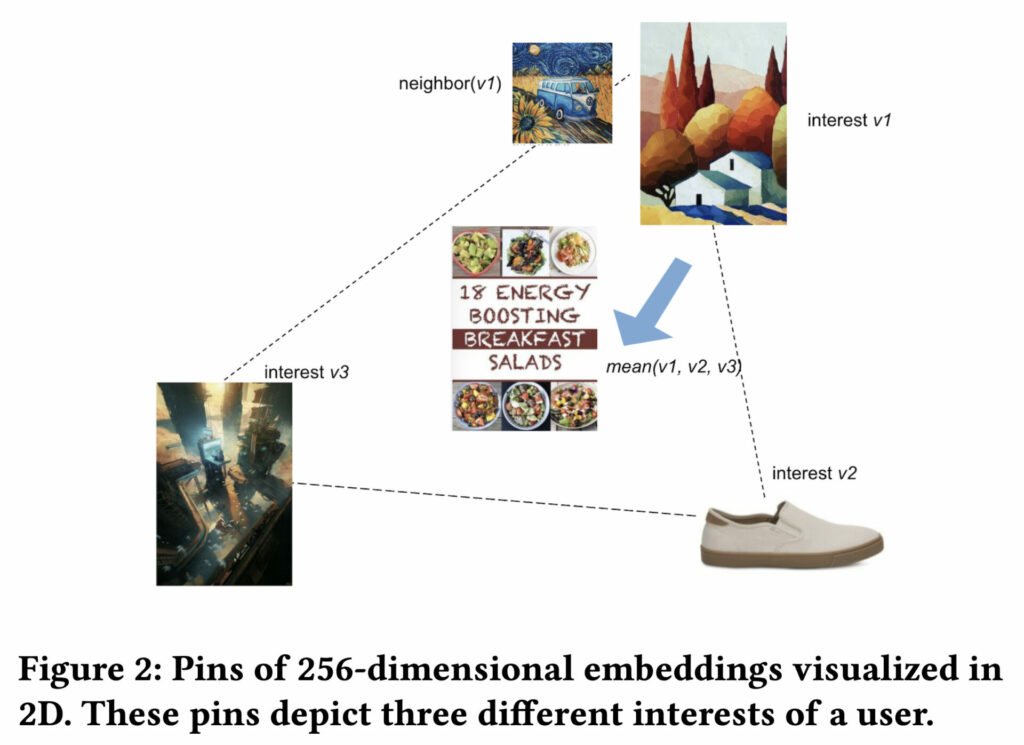
추가로 KMeans 클러스터링을 통해 문제를 해결하던 중 핀터레스트의 PinnerSAGE를 읽게 되었는데, 핀터레스트 역시 동일한 문제를 지적하고, 해결했다는 사실을 알게 되었습니다. 위 그림처럼 동일한 사용자가 서로 다른 토픽을 지닌 여러 핀에 관심을 가질 수 있기 때문에, 이를 임베딩의 평균과 같이 나이브하게 풀게 되면 사용자에게 전혀 관련 없는 핀을 추천해버리게 됩니다.
PinnerSAGE 또한 해당 문제를 클러스터링으로 해결하고자 했으며, KMeans가 아닌 Hierarchical Agglomerative Clustering으로 문제에 접근했습니다. 동일한 문제에 대해 같은 방법으로 해결책을 찾고자 했다는 사실이 반가웠으며, 클러스터링 기법들에 대한 이해를 키워 로직을 개선할 수 있겠다는 가능성을 보여주어 저자진에게 감사한 마음을 갖게 되었습니다 🙏
Item Shuffling: 다양한 문서 노출하기
클러스터링 적용 후, 임베딩 평균이 엉뚱한 곳으로 향하지 않아 사용자에게 보다 알맞은 콘텐츠를 추천할 수 있게 되었습니다. 하지만 이는 세 번째 문제를 야기하게 되었습니다. 예를 들어보겠습니다! 카터의 하이라이트 히스토리에 클러스터링을 적용한 결과 “딥러닝 클러스터”, “UX 클러스터”, “스타트업 문화 클러스터”가 도출되었습니다.
이제 추천 모델은 “딥러닝 문서”, “UX 문서”, “스타트업 문화 문서” 목록을 각각 내뱉어 줄 것입니다. 해당 문서 목록은 사용자에게 어떤 순서로 노출되어야 할까요? 처음에는 큰 고민 없이 사용자가 가장 최근 하이라이트 한 문서가 속한 클러스터에 대한 추천 문서 목록을 사용자에게 우선적으로 노출시켜주면 되겠다고 생각했습니다.
가령 제가 가장 최근 하이라이트한 문서가 딥러닝 관련 문서였을 경우, “딥러닝 문서” 목록을 쭉 나열해주는 방식입니다. 이를 실제로 적용해보니 굉-장히 재미없고 단조로운 추천의 경험이 펼쳐졌습니다. 사용자는 분명 최근 여러 관심사를 라이너에 비추었는데, 딥러닝 문서만 들입다 추천해주는 셈이 된 것이죠. 여기서 추천 목록의 다양성을 보장할 수 있는 방법에 대한 고민이 시작되었습니다.
그리고 해당 문제에 대한 해결책은 생각보다 쉽게 떠올릴 수 있었습니다. 최근 요기요 추천 시스템 글을 재밌게 읽었던 기억이 바로 떠올랐기 때문입니다. 글에 따르면 요기요에서는 사용자에게 치킨 전문점만 추천해주는게 아닌, 다양한 종류의 음식점을 추천해주기 위해 Item Shuffle을 도입하였으며, 이를 위해 스포티파이의 글을 참조했다고 합니다.
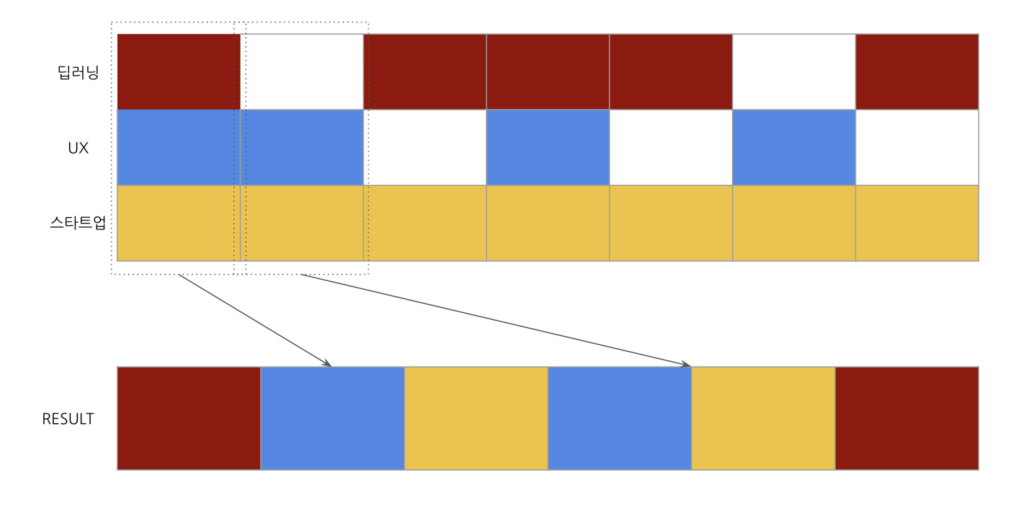
그리고 라이너 역시 스포티파이와 요기요의 사례를 따라 Item Shuffle을 적용하게 되었습니다. 셔플 알고리즘 관련 자세한 내용은 링크된 글을 참고해주시면 감사하겠습니다. 셔플 알고리즘을 적용한 결과, 실제로 이전에 느낀 단조로운 추천에서 벗어나 보다 동적이고 다양한 추천 목록의 구성이 가능해지는 모습을 확인할 수 있었습니다.
마치며…
프로덕션 레벨에서 추천 시스템을 구현하고 운영해보니, 여러 재밌는 다양한 문제를 마주하게 되는 것 같습니다. 글을 통해 소개드린 세 가지 문제는 앞으로 제가 마주하게 될 숱한 문제 중 극히 일부에 불과하겠죠? “오히려 좋아”입니다.
현재는 아직 추천 피쳐가 라이너의 메인 피쳐로 동작하고 있지 않지만, 분명 메인 피쳐가 될 날이 올 것이라 믿고 있기 때문에 열심히 내실을 다져나가는 중입니다. 덕분에 다양한 노하우와 기술력을 쌓아가고 있고, 이는 향후 라이너가 Curation Revolution을 이루는 과정에 큰 무기가 될 것이라 믿습니다.
라이너와 추천 기술을 통해 Curation Revolution을 이루는데 많은 분들이 관심을 가져주시면 좋겠다라는 메아리를 외치며 글을 마치겠습니다. 긴 글 읽어주셔서 정말 감사합니다!
참고 자료
- Re-ranking
- [Recommender System] – 결과 정렬에서의 Shuffle 알고리즘
- How to shuffle songs?
- The art of shuffling music
WANTED: 데이터와 기술로 라이너를 더 단단하게 만들어 주실 분
라이너는 전 세계 750만 사용자와 함께 하는 하이라이팅 기반 정보 탐색 서비스입니다. 기존 텍스트 하이라이트에 YouTube 하이라이트까지 등에 업은 라이너에는 매일 텍스트와 동영상 등 다양한 모달리티의 컨텐츠에 대해 수백만 건의 로그 데이터가 쌓이고 있습니다.

라이너는 데이터를 활용해 사용자가 원하는 발전을 위해 소비해야 할 컨텐츠를 큐레이팅 해주는 역할을 대신해주고자 합니다. 라이너가 해결하고자 하는 문제를 풀어줄 모델링을 하고 싶은 머신러닝 사이언티스트, 추론 엔진을 750만 사용자에게 쾌적하게 서빙해보고 싶은 머신러닝 엔지니어 외에도 데이터를 과학적으로 혹은 엔지니어링적으로 잘 다루시는 모든 분들을 기다리고 있습니다!