Graph in LINER : 글로벌 추천 프로덕트에 GNN 적용하기
안녕하세요, LINER의 머신러닝 엔지니어 타일러입니다. 🫡
오늘은 GNN을 LINER의 문서 추천시스템에 적용한 프로젝트에 대해 소개 드리려고 합니다.
LINER Services 🔍

LINER는 정보 탐색을 혁신하는 글로벌 플랫폼을 지향하고 있습니다. 이를 위해 하이라이팅, 문서 추천, 최근엔 LLM을 이용한 생성형 검색과 코파일럿 까지 다양한 서비스를 전개하고 있는데요.
이 서비스들은 두 가지 공통점을 갖고 있습니다. 첫 번째는 모두 “유저가 더욱 빠르게 똑똑해질 수 있도록 돕는 서비스”라는 것이고, 두 번째는 “그 과정에서 유저가 문서와 상호작용 한다는 것”입니다.
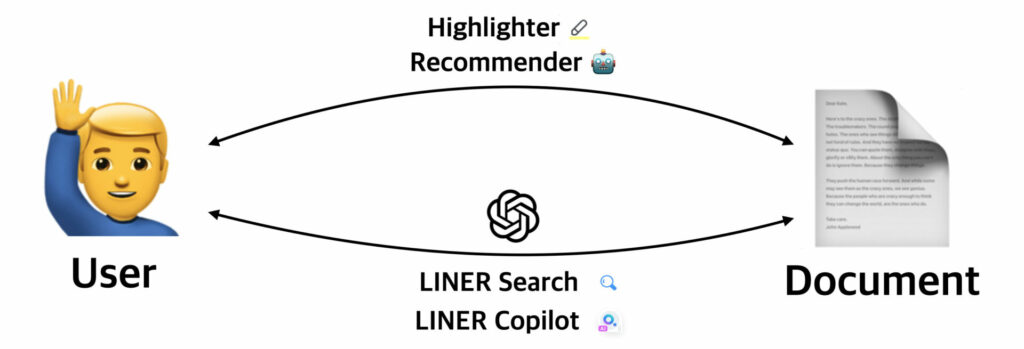
하이라이팅과 코파일럿은 유저가 문서를 소비하는 과정 자체를 돕고, 추천은 유저가 관심있는 문서를 받아볼 수 있도록 돕습니다. 생성형 검색은 유저의 검색 의도에 맞는 문서를 찾고 가공해서 보여줍니다. 이렇듯 서비스에 빠짐없이 등장하는 “유저와 문서의 상호작용”은 LINER 서비스의 핵심요소라고 볼 수 있습니다.
Graph 🔗
저희는 어떻게하면 “유저와 문서의 상호작용”으로 구성된 문제들을 잘 풀 수 있을지에 대해 항상 고민해왔습니다. 머신러닝 관점에선, “상호작용”을 추천에 녹이는 방법을 특히 많이 고민했는데요. LINER 블로그에서도 그 흔적들을 쉽게 찾아볼 수 있습니다. [Thompson Sampling] [Session Recommender]
그 고민의 답 중 하나가 바로 Graph입니다. Graph는 데이터 자체에 상호작용을 효과적으로 녹여낼 수 있는 방법 인데요. 구체적으로 Graph는 현실의 다양하고도 복잡한 상호작용을 모델링하기 위한 자료구조로, Node와 Link(Edge)라는 두 가지 구성요소로 이루어져 있습니다.
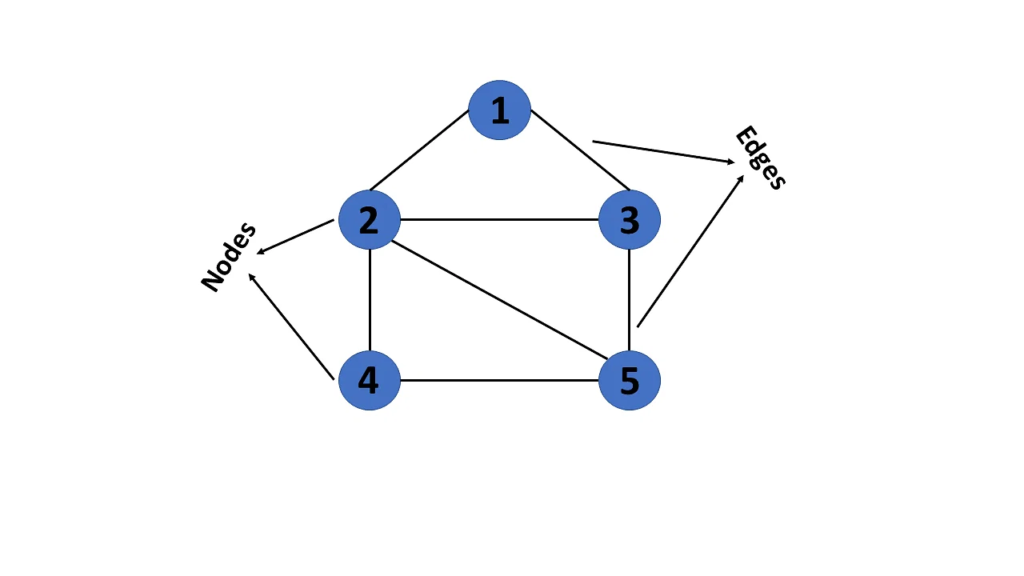
(출처: www.simplilearn.com)
Node는 객체와 같은 개념으로서, LINER에선 각각의 유저와 문서가 이에 대응됩니다. Link는 Node간의 연결을 표현하는 개념으로서, 하이라이팅과 추천 노출/소비, 코파일럿 사용 등의 Action이 Link에 해당됩니다.
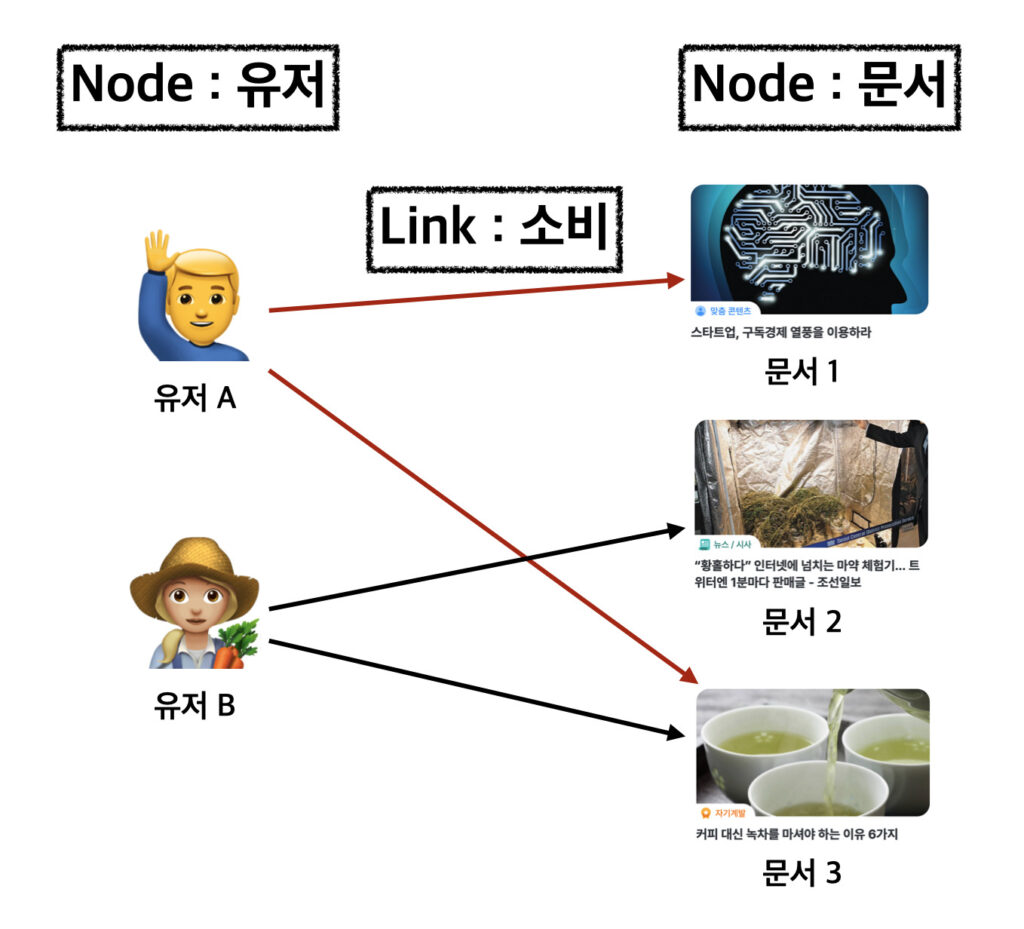
Graph를 사용하면 Node와 Link 자체의 정보에 더해 상호작용이 만들어내는 복합적인 정보까지 포착해낼 수 있습니다. 이러한 장점 때문에 상호작용이 중요한 Task를 푸는 연구들에선 Transformer 만큼이나 Graph 기반 방법론들이 강력한 성능을 보이기도 합니다.
Graph in Recsys 🤖
이렇게 강력한 Graph는 사실 LINER의 추천 시스템에 이미 적용되어 있었습니다. [LINERVA-WALK](이하 Walk)가 그것인데요. Random Walk 기반의 간단하지만 강력한 구조로, 지금까지도 LINER 추천 시스템에 큰 기여를 하고 있는 모델입니다.
그러나 Walk는 Random Walk를 통해 얻어진 방문 횟수만을 사용한다는 한계를 갖고 있습니다. 저희는 Link 여부 뿐만 아니라 Graph가 갖고 있는 풍부한 정보를 최대한 많이 추천에 녹여내고 싶었기에, Graph Neural Network(이하 GNN)을 추천에 도입하기로 했습니다.
(출처: CS224W)
GNN in Recsys 🕸
GNN을 추천에 성공적으로 도입하기 위해서는 LINER의 Graph가 갖는 특성을 먼저 파악해야 했습니다. 가장 대표적인 특징은 유저와 문서가 시간이 지남에 따라 계속 증가하므로, Graph가 계속 커진다는 것입니다. 따라서 새롭게 추가되는 Node에 대해서도 모델이 동작할 수 있어야 합니다.
(출처: Efficient Algorithms to Mine Maximal Span-Trusses From Temporal Graphs)
또, 핵심 Node인 문서의 Feature가 비교적 풍부한 편입니다. 문서를 이루고 있는 글, 이미지 모두 Feature로 사용이 가능합니다. 따라서 Node의 Feature를 적극적으로 사용하는 모델일수록 좋습니다.

이러한 특성을 바탕으로 여러 연구를 찾아 보았고, 아래의 세 가지 연구의 아이디어를 적용하기로 결정합니다.
– GraphSAGE
Inductive Representation Learning on Large Graphs (리뷰)
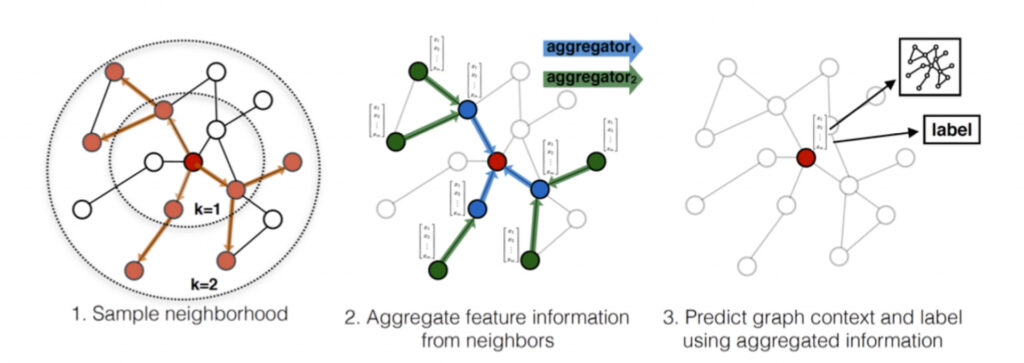
GraphSAGE는 관심있는 Node와 연결되어있는 Node 몇개를 추출해 Local-Graph를 만들고, 연결되어있는 Node(이하 이웃)의 Feature로 부터 정보를 가져오는 방법을 NeuralNet으로 학습하는 GNN 모델입니다. 전체 Graph가 아닌, 가까운 이웃을 이용해 학습하기 때문에 학습때 등장하지 않았던 새로운 Node가 추가되더라도 이웃과 Feature만 있다면 좋은 성능을 보입니다. 이러한 특징이 새로운 Node가 끊임없이 추가되는 LINER Graph 에 적합하다고 판단했습니다.
– GAT
Graph Attention Networks (리뷰)
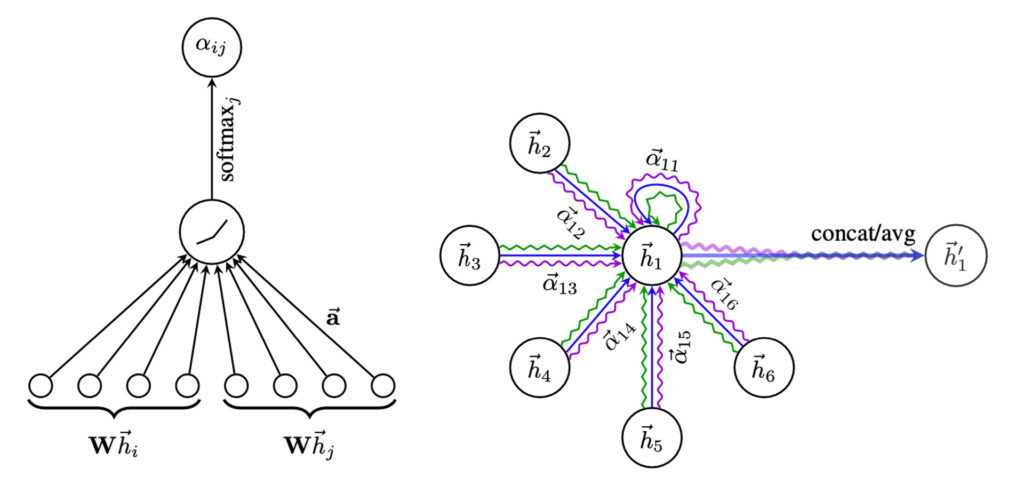
GAT는 이웃으로 부터 정보를 가져올 때 모든 이웃의 정보를 동등하게 가져오는 대신, Attention을 이용하는 GNN 모델입니다. Node를 가장 잘 표현할 수 있는 이웃들로부터 정보를 가져오기에 일반적으로 더 좋은 성능을 보입니다.
– Max Margin Ranking Loss
Graph Convolutional Neural Networks for Web-Scale Recommender Systems (리뷰)
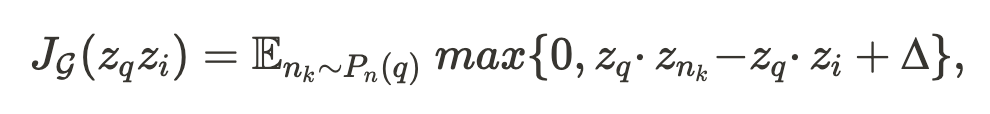
Max Margin Ranking Loss는 Anchor, Positive, Negative 세 개의 데이터 포인트를 이용한 Loss 입니다. 구체적으로는 Anchor ↔ Positive 간의 거리가, Anchor ↔ Negative 간의 거리보다 Margin 이상으로 가깝도록 유도합니다. 유저가 상호작용한 아이템을 더 높은 순위로 예측하고, 상호작용하지 않은 아이템들과의 거리를 멀게 유지하여 개인화된 추천을 위한 학습을 가능하게 합니다.
LINER GNN
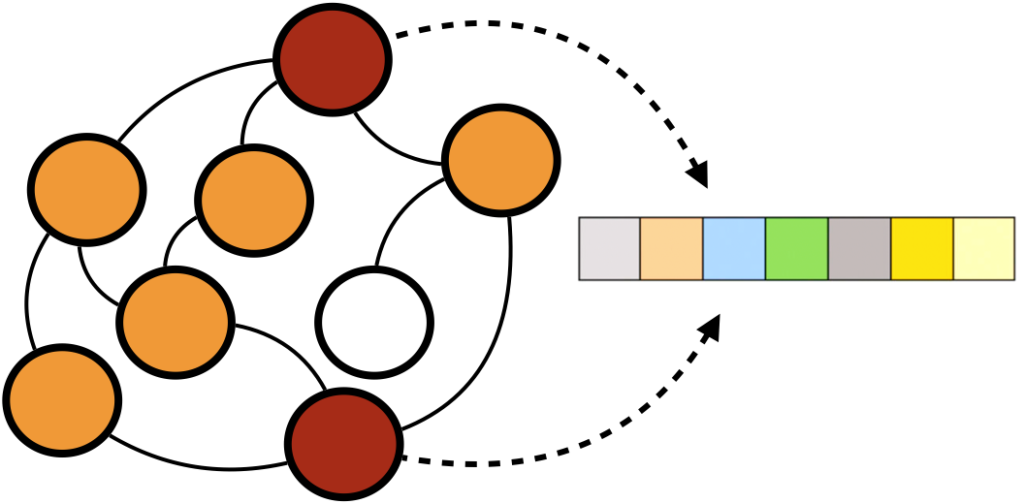
위의 세 가지 방법론의 핵심 아이디어들을 알맞게 조합해 LINER의 데이터와 Task에 알맞는 커스텀 GNN 모델을 만들었습니다. 구체적으로는 Node Feature로 문서의 본문, 언어, 이웃의 수를 사용하였고, 유저가 연속으로 소비한 Document Pair를 Positive Sample로 사용했습니다.
Evaluation 📊
개발한 Custom LINER GNN을 두 가지 방법으로 평가했습니다.
첫 번째로는 Nearest Neighbor Search를 통해 추천 후보를 Retrieval 해오는 모델로서 GNN을 평가했습니다. 학습과정에 등장한 적 없는 이웃 문서 Pair에 대해 Top-K Nearest Neighbor안에 서로가 포함되는지를 계산했는데요(Recall@K). 기존 Text 기반의 문서 Embedding과 비교해, 압도적인 성능을 보여주었습니다. (좌측 표)
두 번째로는 다른 Retrieval Model에 들어가는 Embedding 모델로서 GNN을 평가했습니다. 기존에 존재하는 Sequential Recommender의 문서 Embedding을 GNN Embedding으로 대체해서 위와 같은 방식으로 Metric을 측정했는데요(Recall@K). 이 또한 압도적인 성능을 보여주었습니다. (우측 표)
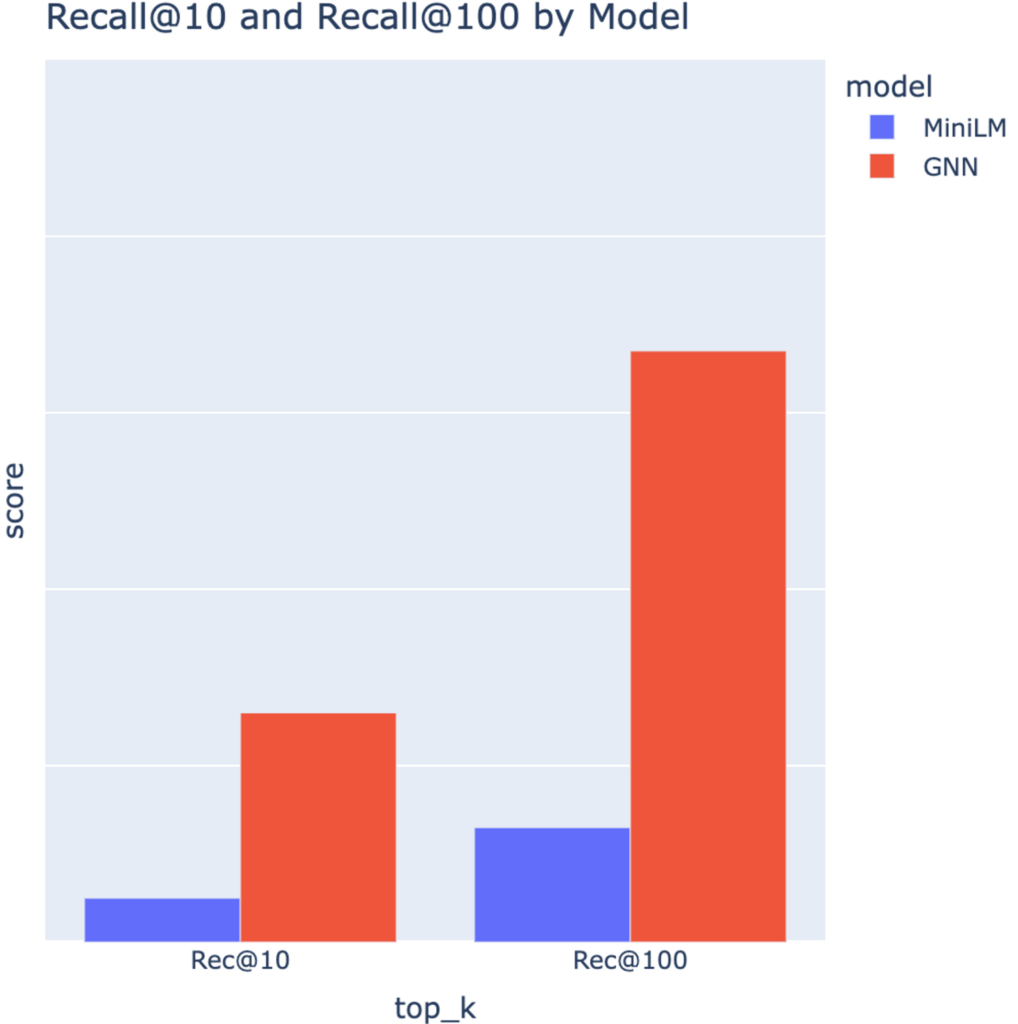
(표 1) Retrieval Model로서 MiniLM과 비교
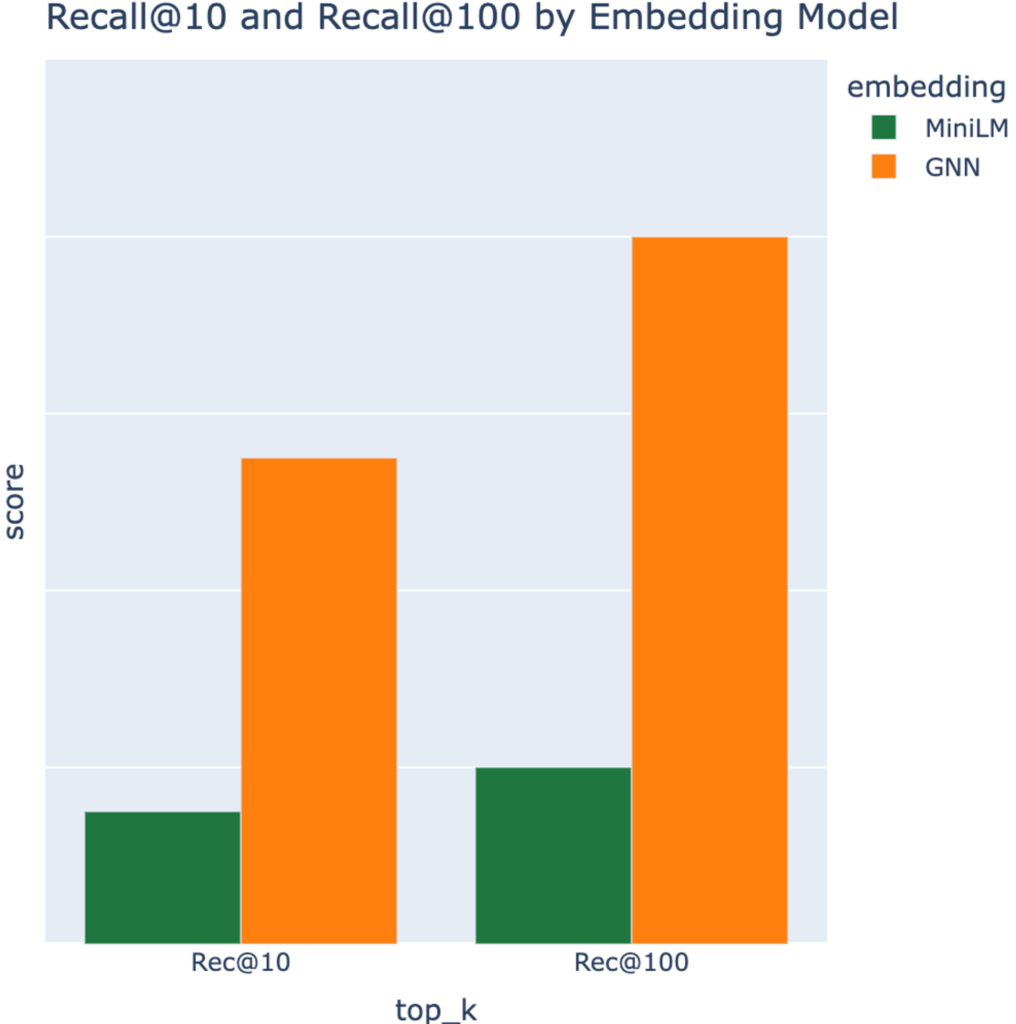
(표 2) Embedding Model로서 MiniLM과 비교
Offline Evaluation에서의 성공적인 결과에 힘입어 바로 Production에 GNN을 배포하기로 결정했고, Embedding 모델의 교체보다는 비교적 인프라 구성이 쉬운 Retrieval Model로서의 GNN을 우선 배포하였습니다.
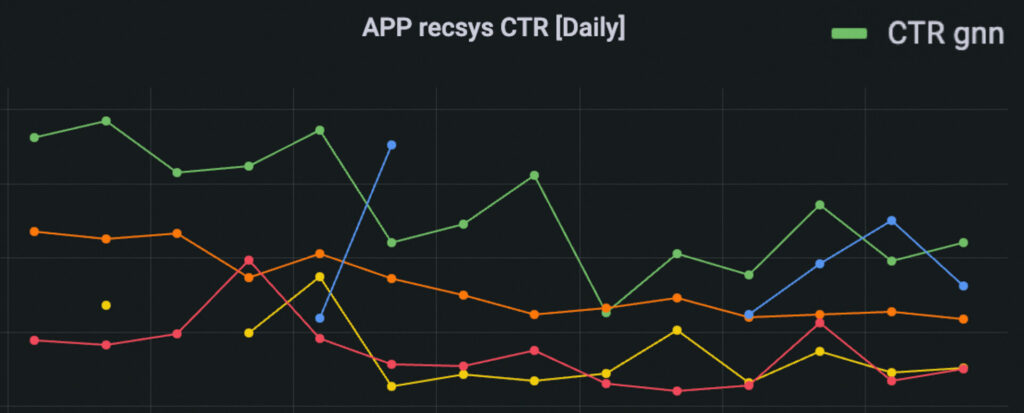
이렇게 배포된 Retrieval GNN은 배포 이후 App기준 CTR 1~2위를 다투며, 추천 경험 개선에 큰 기여를 하고 있습니다. 유저와 문서의 상호작용이 깊게 녹아든 모델인 만큼, 내용이 유사한 문서를 넘어 유저와 문서의 관계를 잘 파악한 추천이 이루어져 높은 CTR을 보인다고 해석하고 있습니다.
Outro
LINER의 서비스들은 “유저와 문서의 상호작용”을 핵심으로 갖고 있습니다. 따라서, 오늘 소개드린 추천 후보 Retrieval 모델로서의 GNN 외에도 서비스에 GNN이 적용될만한 여지가 무궁무진한데요. 예를 들면 추천 후보의 개인화된 Ranking을 매기는 모델로서도 동작할 수도 있고, LLM이 그라운딩할 문서를 찾는 과정에서, GNN을 이용해 개인화 요소를 넣어줄 수도 있겠죠.
이렇듯 LINER에선 ML을 이용해 유저의 정보탐색을 혁신할 수 있는 도전적이고, 재미있는 문제가 많이 있습니다. 저희와 함께 이런 문제들을 함께 풀어나가며, 세상을 바꾸어 나가실 분들을 찾고 있습니다. 글을 보면서 LINER의 정보 탐색 혁신에 흥미가 생기셨거나, ‘도전’, ‘문제’와 같은 말에 가슴이 뛰는 분이 있다면 언제든지 연락주세요!